# Make a lineup of mtcars data
# 20 plots, one data, 19 nulls
# Which one is different?
set.seed(20190709)
library(ggplot2)
ggplot(
lineup(
null_permute('mpg'),
mtcars),
aes(mpg, wt)
) +
geom_point() +
facet_wrap(~ .sample)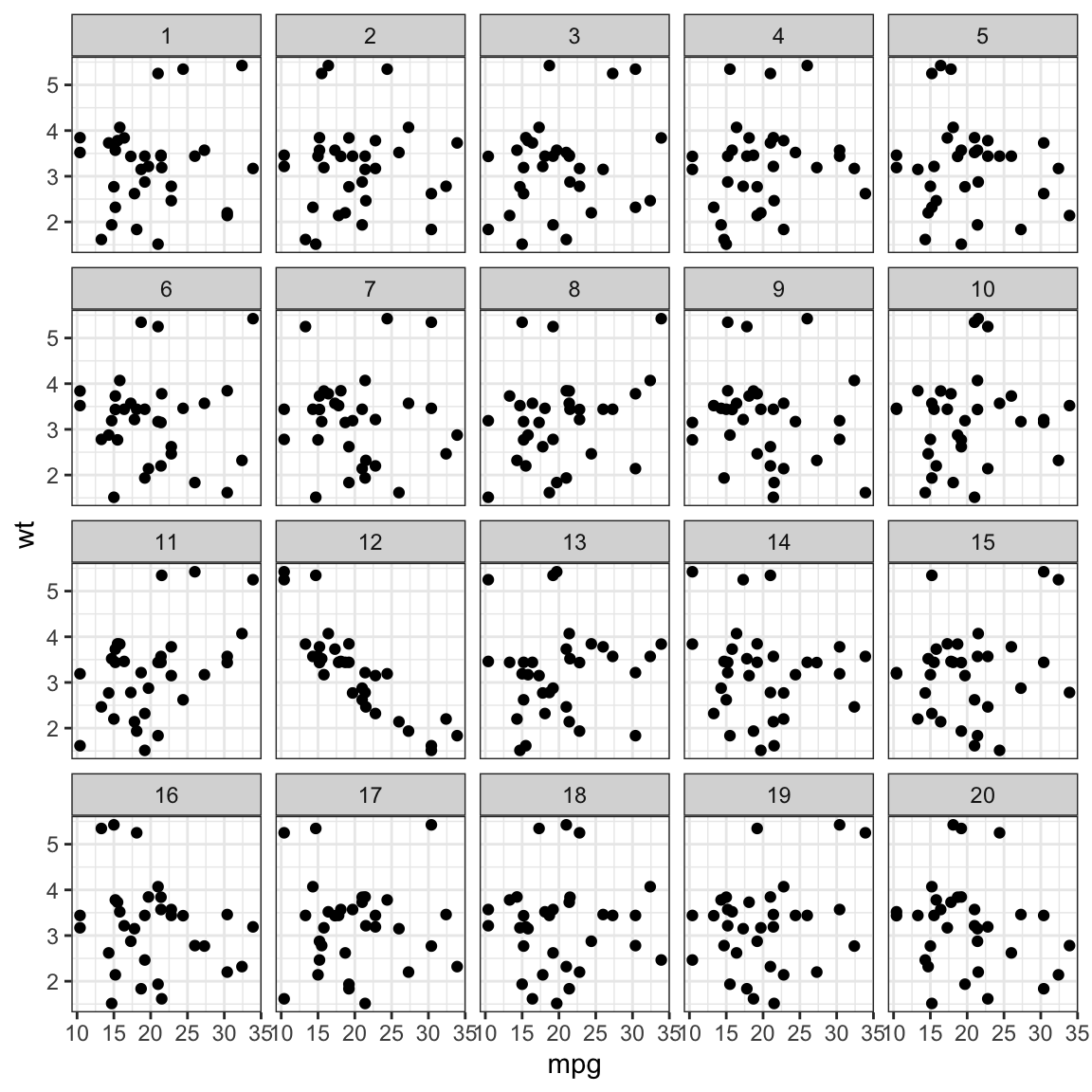
SISBID 2025
https://github.com/dicook/SISBID
\[\begin{align}X &= \left[ \begin{array}{rrrr} X_1 & X_2 & ... & X_p \end{array} \right] \\ &= \left[ \begin{array}{rrrr} X_{11} & X_{12} & ... & X_{1p} \\ X_{21} & X_{22} & ... & X_{2p} \\ \vdots & \vdots & \ddots& \vdots \\ X_{n1} & X_{n2} & ... & X_{np} \end{array} \right]\end{align}\]
Inferring that what we see in the data at hand holds more broadly in life, society and the world.
Why do we need it for graphics?
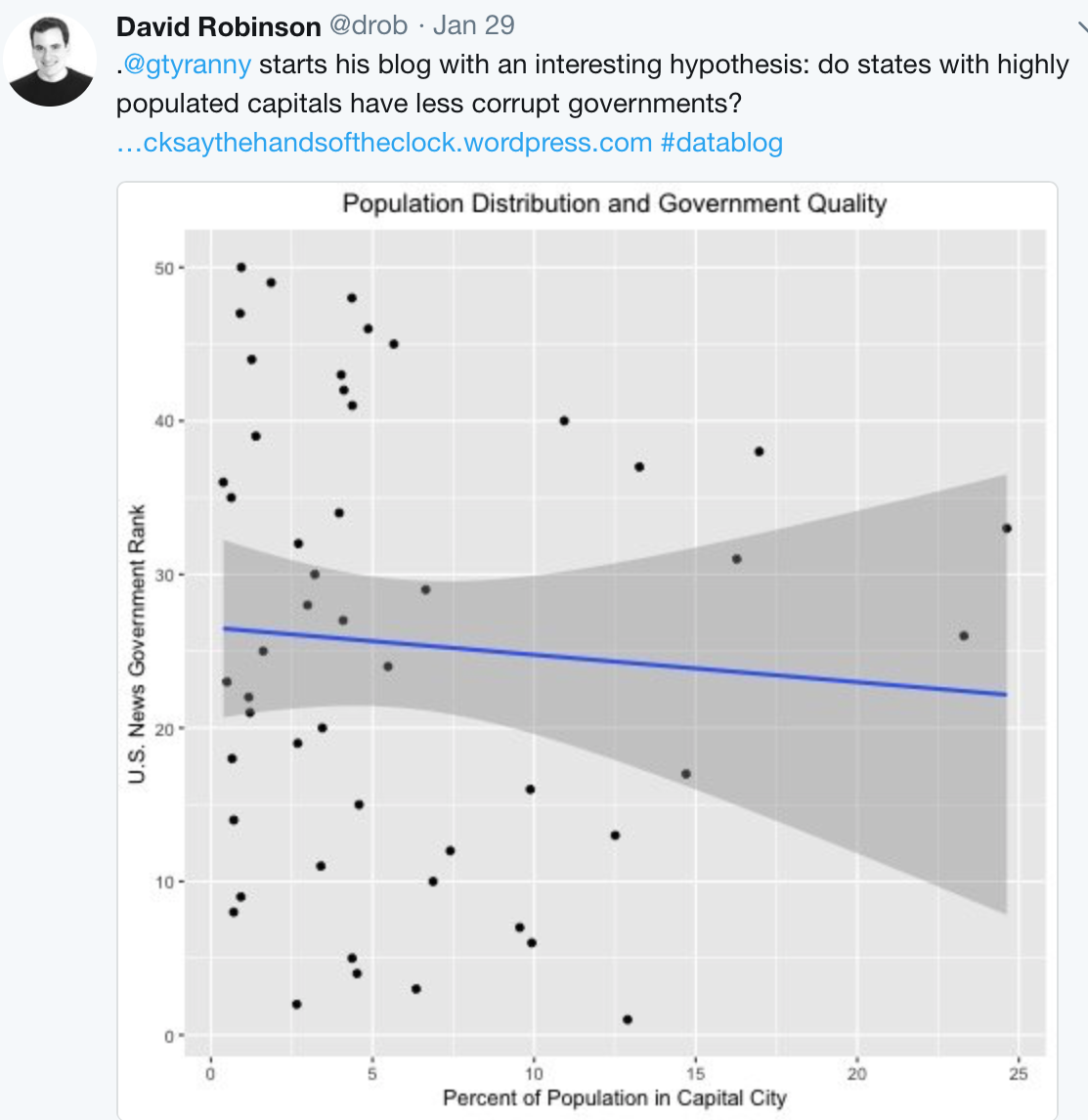
Here’s an example tweeted by David Robinson based on an analysis in Tick Tock blog by Graham Tierney
From the blog: > I ran linear regressions of government rank on the percentage of each state’s population living in the capital city, state population (in 100,000s), and state GDP (in $100,000s)…. The coefficient is not significant for any regression at the traditional 5% level.
… I’m not convinced that the lack of significance is itself significant.
You need a:
You need a:
Here are several plot descriptions.
What would be the null hypothesis in each?
Which plot definition would best match
\(H_0:\) there is no difference in the distribution between the groups?
A - doesn’t show by group, so not useful. Would allow testing association between x1, x2 across groups. B - could be useful to show differences in mean on (x1, x2) by cl C - might allow testing whether distribution of x1 is symmetric D - Might show differences in distribution for x1
Here are several null hypotheses.
What type of plot would you use to test each?
x1 and x2clx1 is XXXx1 b/w levels of cl
# Make a lineup of mtcars data
# 20 plots, one data, 19 nulls
# Which one is different?
set.seed(20190709)
library(ggplot2)
ggplot(
lineup(
null_permute('mpg'),
mtcars),
aes(mpg, wt)
) +
geom_point() +
facet_wrap(~ .sample)
Example from the nullabor package. The data plot is embedded randomly in a field of null plots, this is a lineup. Can you see which one is different?
When you run the example yourself, you get a decrypt code line, that you run after deciding on a plot to print the location of the data plot amongst the nulls.
Mix the data plot
into a field of null plots
Which plot is different?
Assuming that all plots in a lineup are equally likely to be selected,
\[P(X\geq x) = \sum_{i=x}^{K} \binom{K}{i} \left(\frac{1}{m}\right)^i\left(\frac{m-1}{m}\right)^{K-i}\]
\[P(X\geq x) = \sum_{i=x}^{K} \binom{K}{i} \left(\frac{1}{m}\right)^i\left(\frac{m-1}{m}\right)^{K-i}\]
This is a Binomial model
For \(x=4\) picks, \(K=17\) observers, \(m=20\) plots
x simulated binom
[1,] 4 0.0202 0.008800605But… some null plots are more visually salient!
Introduce a parameter \(\alpha\): visual salience of null plot dist
\[\begin{align}P(X \geq x) = &\sum_{i = x}^{K} \binom{K}{x} \frac{1}{B(\alpha, (m-1)\alpha)}\times \\ &B(x+\alpha, K-x+(m-1)\alpha),\end{align}\]
where \(B(.,.)\) is the Beta function.
This is a Beta-Binomial mixture model
Computing p-values with \(\alpha\):
alpha = 0.01 alpha = 0.15 alpha = 1
0.03397441 0.25942593 0.47220162 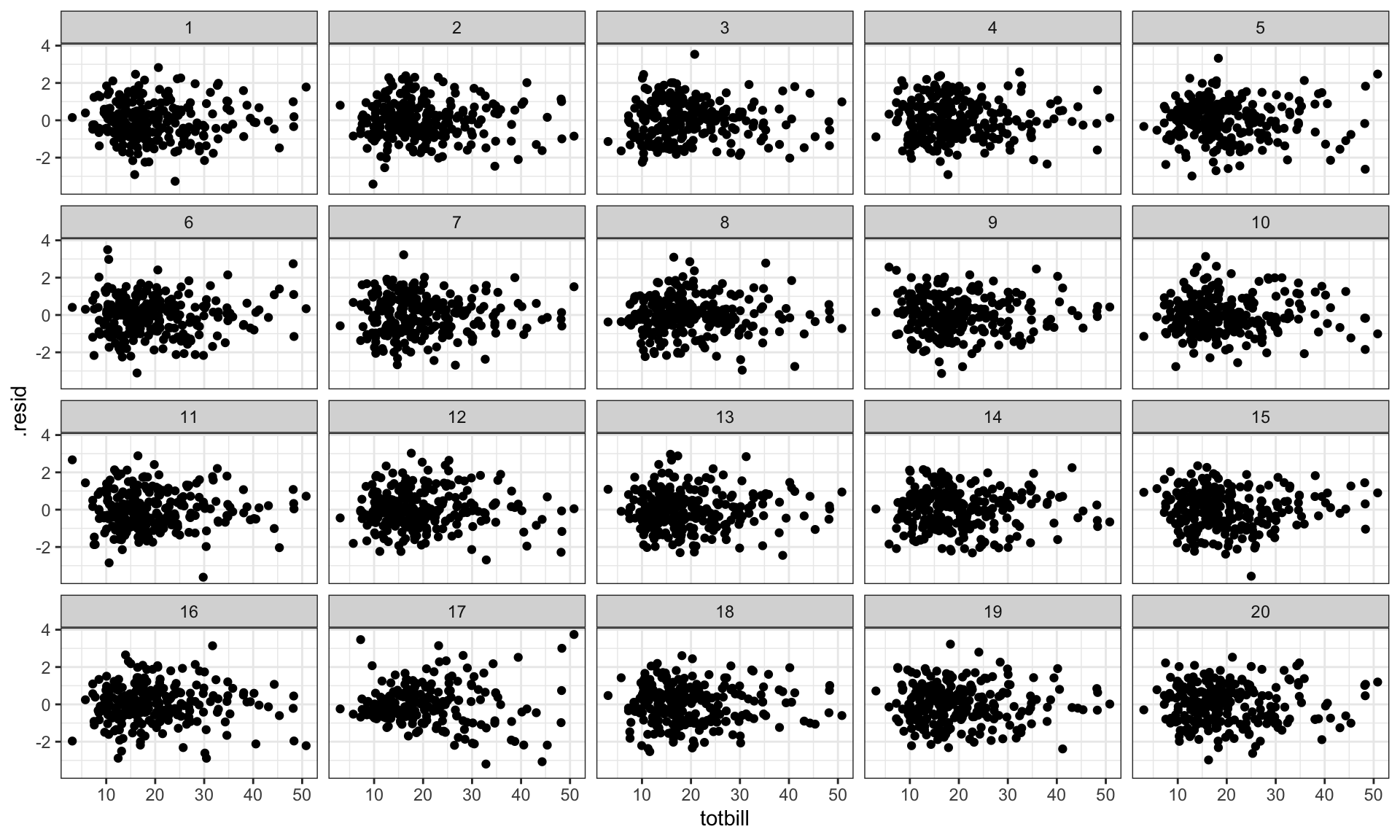
ggplot(l, aes(x=date, y=rate)) +
geom_line() +
facet_wrap(~.sample,
scales="free_y") +
theme(axis.text =
element_blank()) +
xlab("") + ylab("")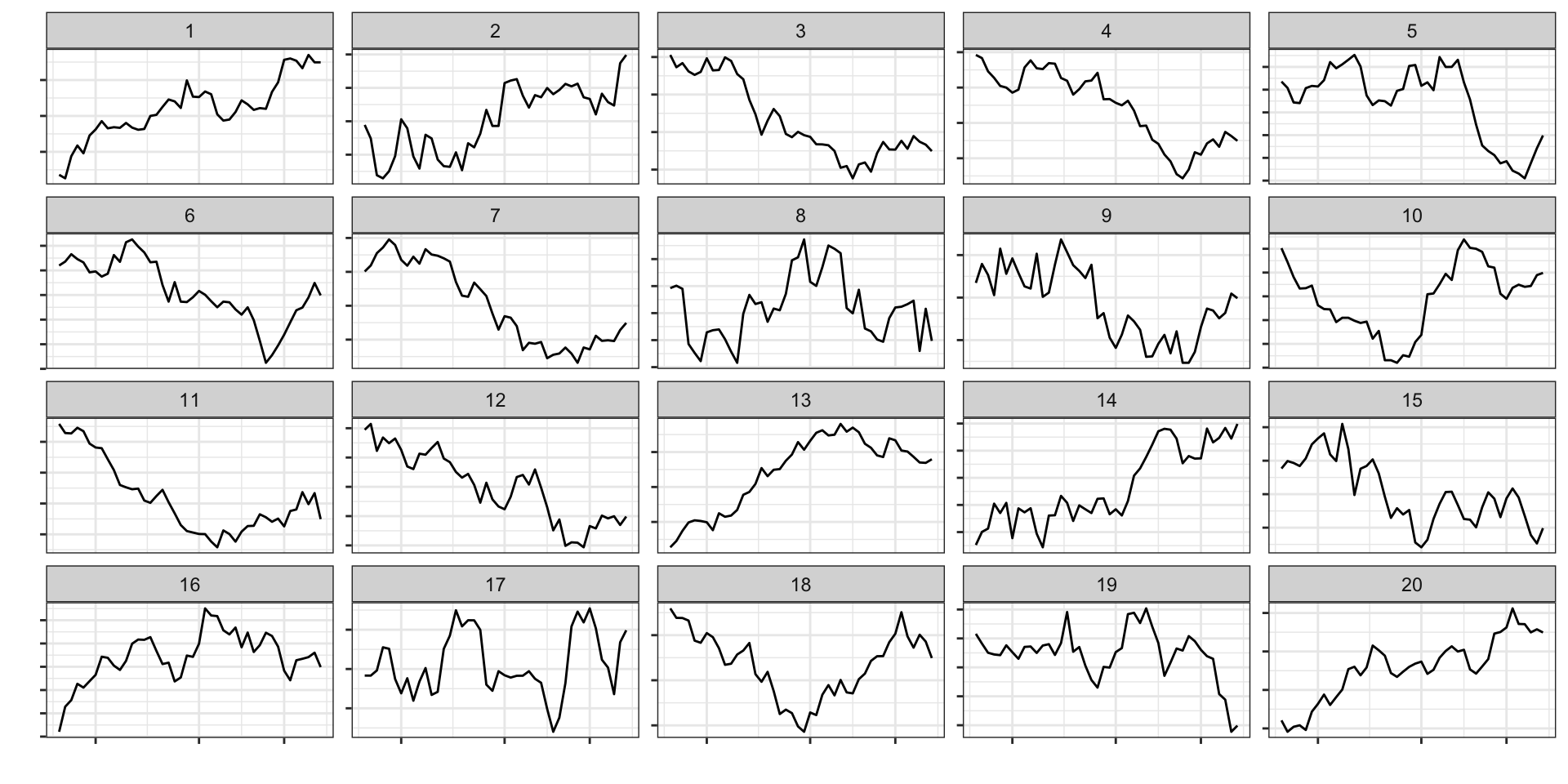
Earlier:
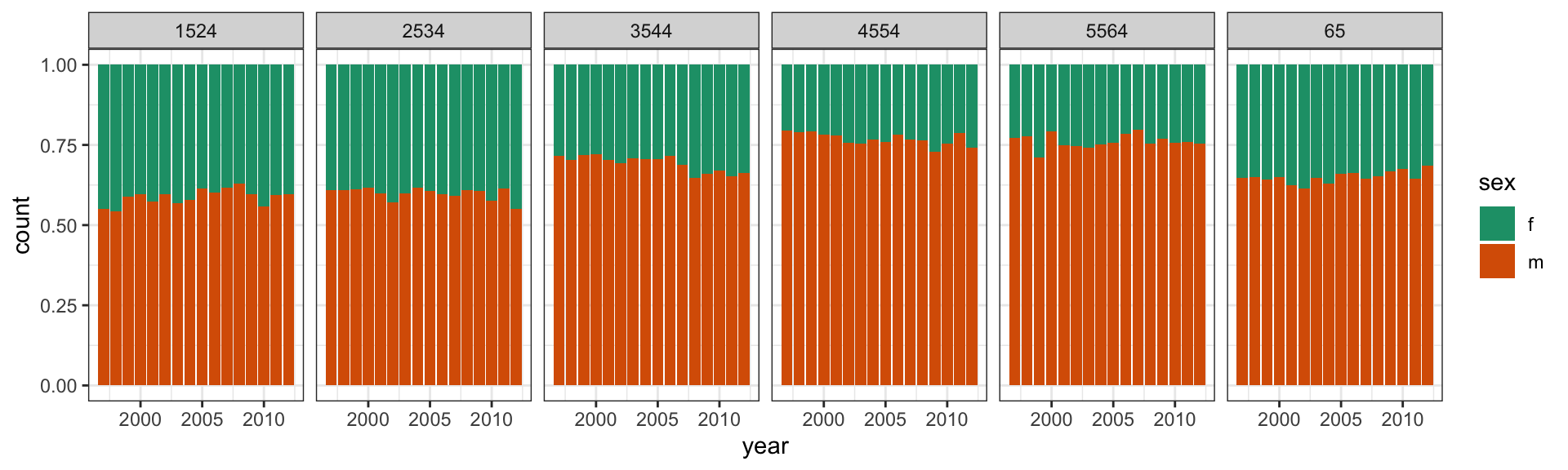
Plot count against year, separately for each age group, coloured by sex.
\(H_0\): TB occurs equally among men and women, regardless of age and year.
\(H_A\): It doesn’t.
# Make expanded rows of categorical variables matching the
# counts of aggregated data. Sex needs to be converted to 0, 1
# to match binomial output.
tb_us_long <- uncount(tb_us, count)
tb_us_long <- tb_us_long |>
mutate(sex01 = ifelse(sex=="m", 0, 1)) |>
select(-sex)
# Generate a lineup of n=3, randomly choose the data position.
# Compute counts again.
pos = sample(1:3, 1)
l <- lineup(null_dist(var="sex01", dist="binom",
list(size=1, p=0.5)),
true=tb_us_long, n=3, pos=pos)
l <- l |>
group_by(.sample, year, age) |>
count(sex01)ggplot(l, aes(x = year, y = n, fill = factor(sex01))) +
geom_bar(stat = "identity", position = "fill") +
facet_grid(.sample ~ age) +
scale_fill_brewer(palette="Dark2") +
theme(legend.position="none")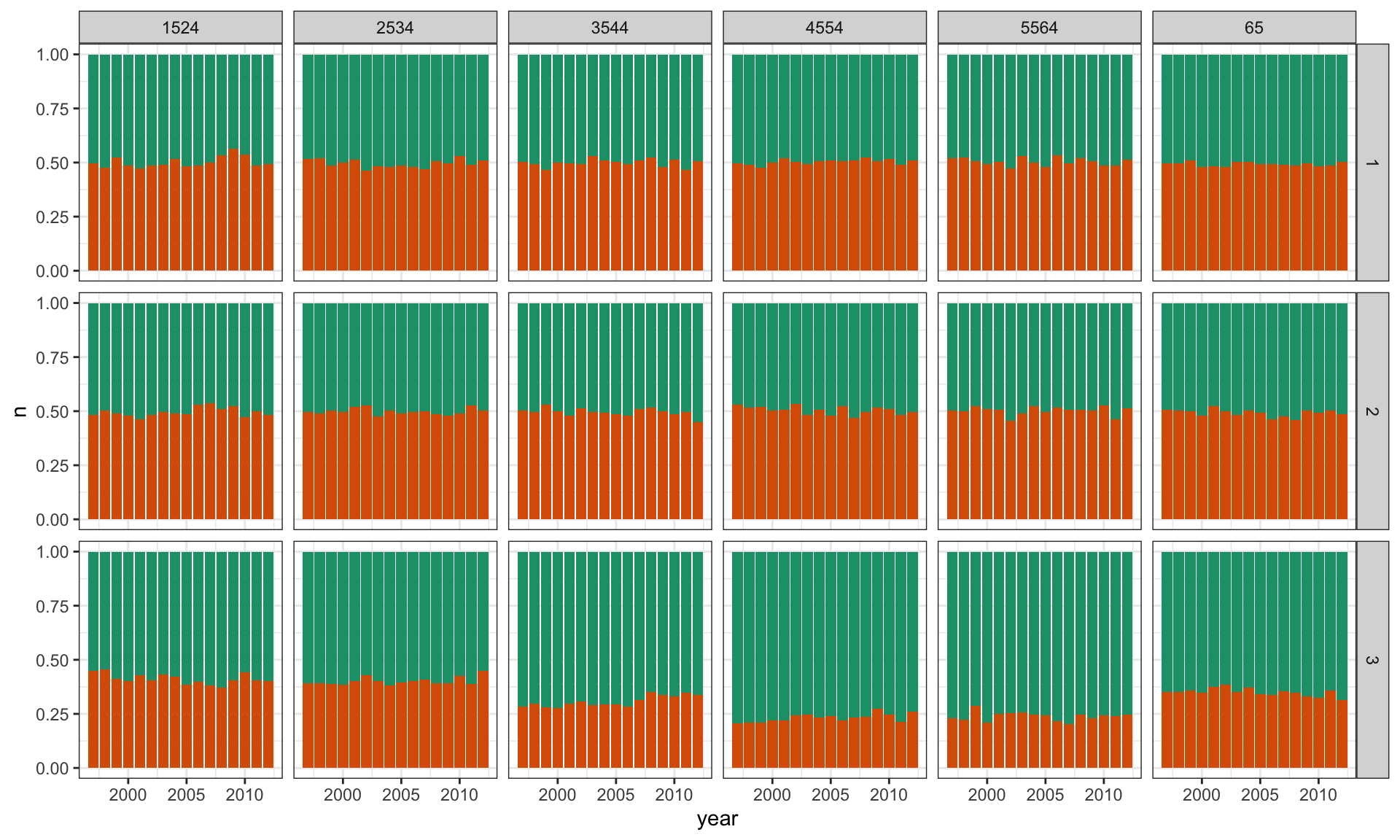
\(H_0\): Rates are the same across sex, regardless of age and year.
\(H_A\): They aren’t.
tbl <- tb_us |> group_by(sex) |> summarise(count=sum(count))
tbl
p <- tbl$count[1]/sum(tbl$count)
pos = sample(1:3, 1)
l <- lineup(null_dist(var="sex01", dist="binom",
list(size=1, p=p)),
true=tb_us_long, n=3, pos=pos)
l <- l |>
group_by(.sample, year, age) |>
count(sex01)# A tibble: 2 × 2
sex count
<chr> <dbl>
1 f 25915
2 m 55640ggplot(l, aes(x = year, y = n, fill = factor(sex01))) +
geom_bar(stat = "identity", position = "fill") +
facet_grid(.sample ~ age) +
scale_fill_brewer(palette="Dark2") +
theme(legend.position="none")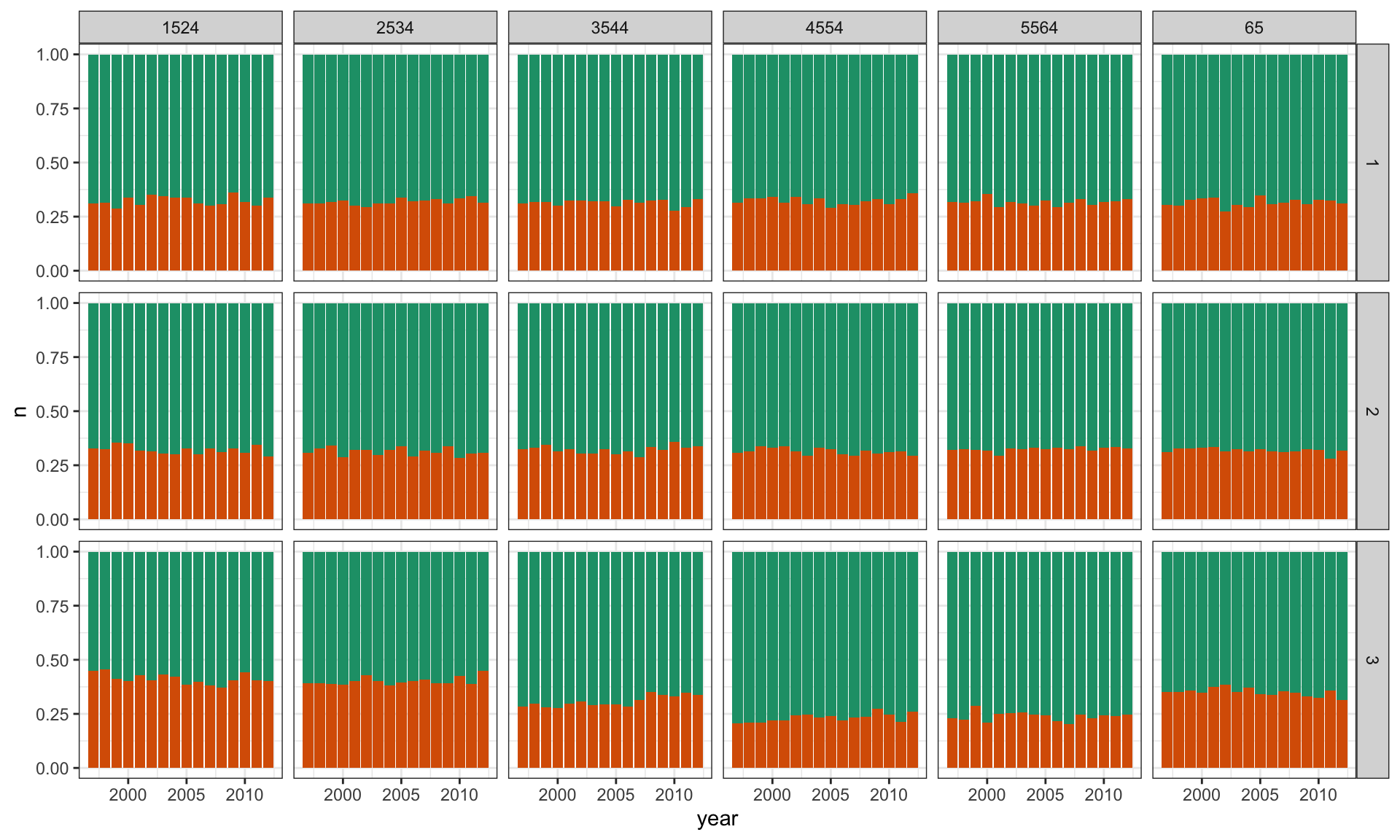
\(H_0\) is determined based on the plot type
\(H_0\) is not based on the structure seen in the data set
Null data creation method does not match characteristics of original sample other than that in \(H_0\)
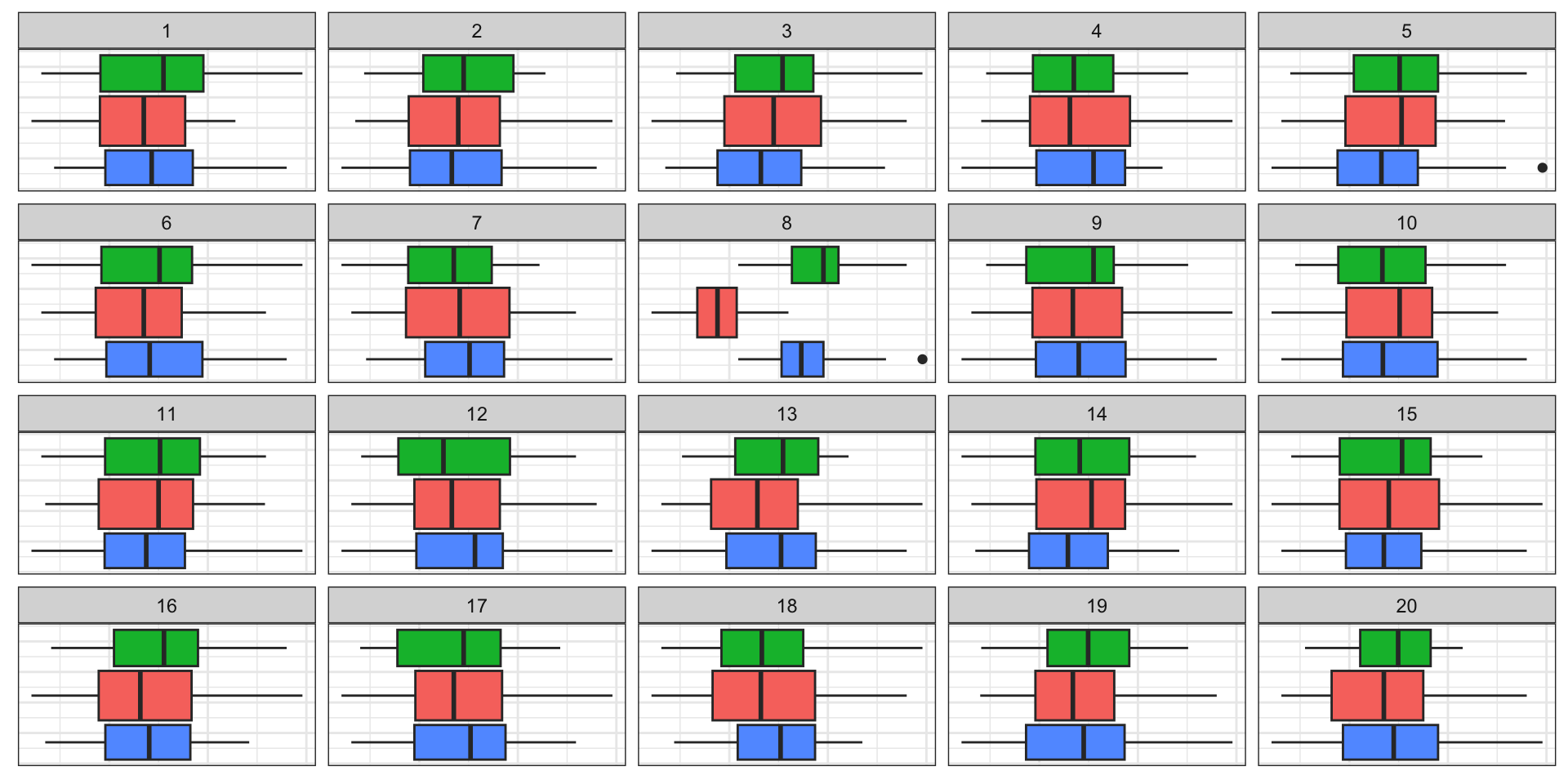
Does one map show a spatial trend?
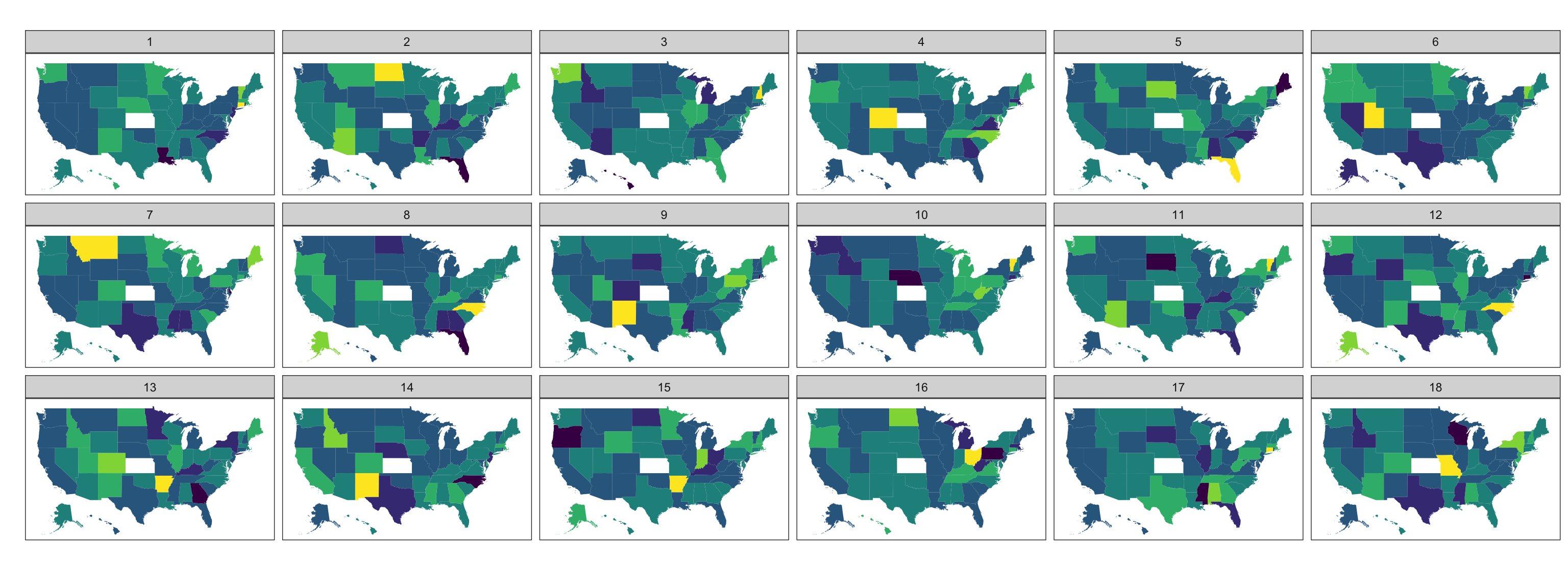

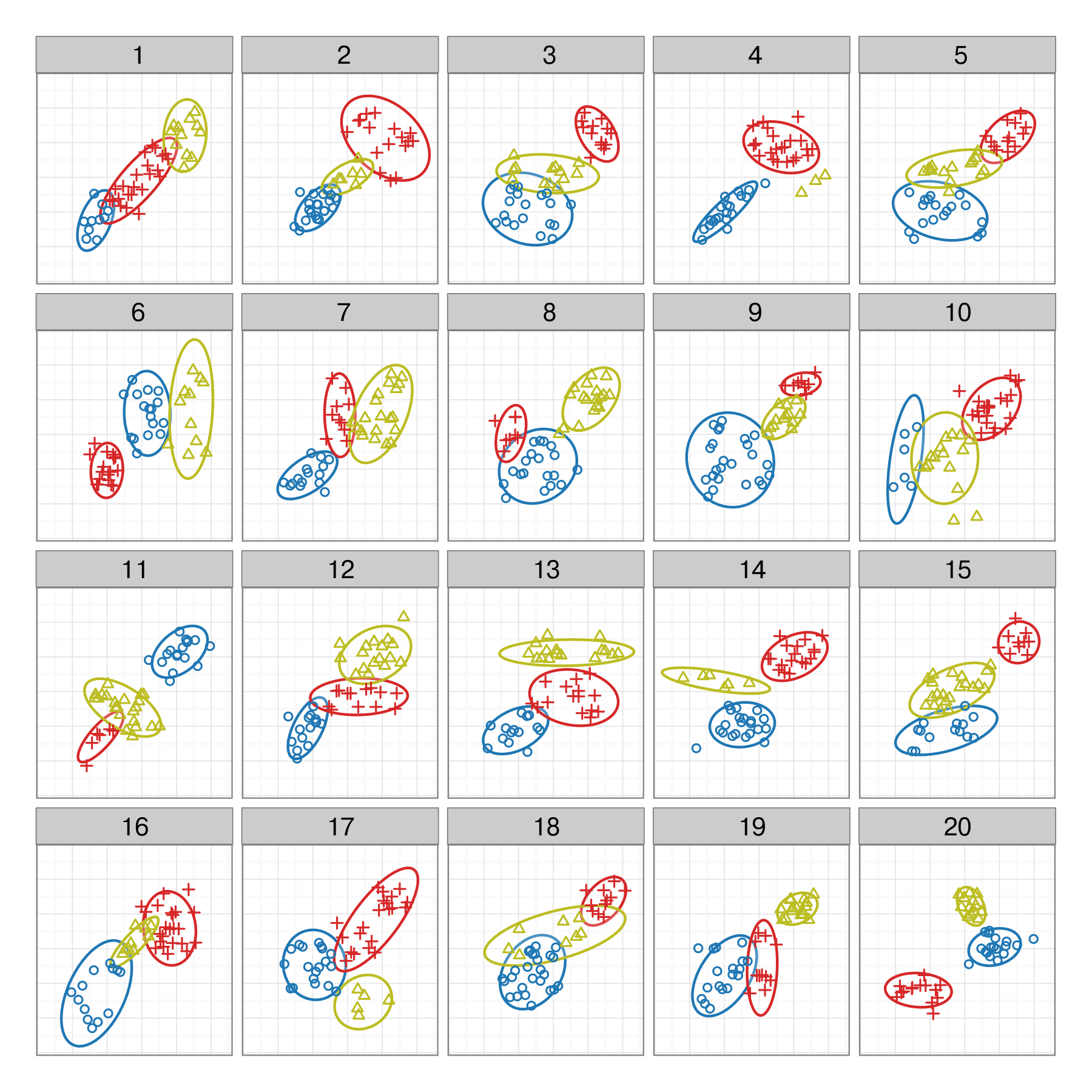
decrypt linex for your grouppvisual function to compute the p-value, K= group size, m=18pVis - how much difference does it make?data(wasps)
lda_pred <- function(x) {
d <- predict(lda(Group~.,
data=x[,-43]))$x[,1:2] |>
as_tibble() |>
mutate(Group = x$Group)
return(d)
}
wasps_lineup <- lineup(null_permute('Group'),
wasps[,-1], n=12) |>
as_tibble()
wasps_lineup_lda <- wasps_lineup |>
split(.$.sample) |>
map_df(~lda_pred(.)) |>
mutate(.sample = wasps_lineup$.sample)
ggplot(wasps_lineup_lda, aes(x=LD1, y=LD2,
colour=Group)) +
geom_point() +
facet_wrap(~.sample, ncol=4) +
scale_colour_brewer(palette="Dark2") +
theme(legend.position="none")Enter the p-value in the chat!
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.