# A tibble: 6 × 3
sex age count
<chr> <chr> <dbl>
1 m 15-24 4893
2 m 25-34 8149
3 m 35-44 5302
4 m 45-54 2493
5 m 55-64 1099
6 m 65+ 669
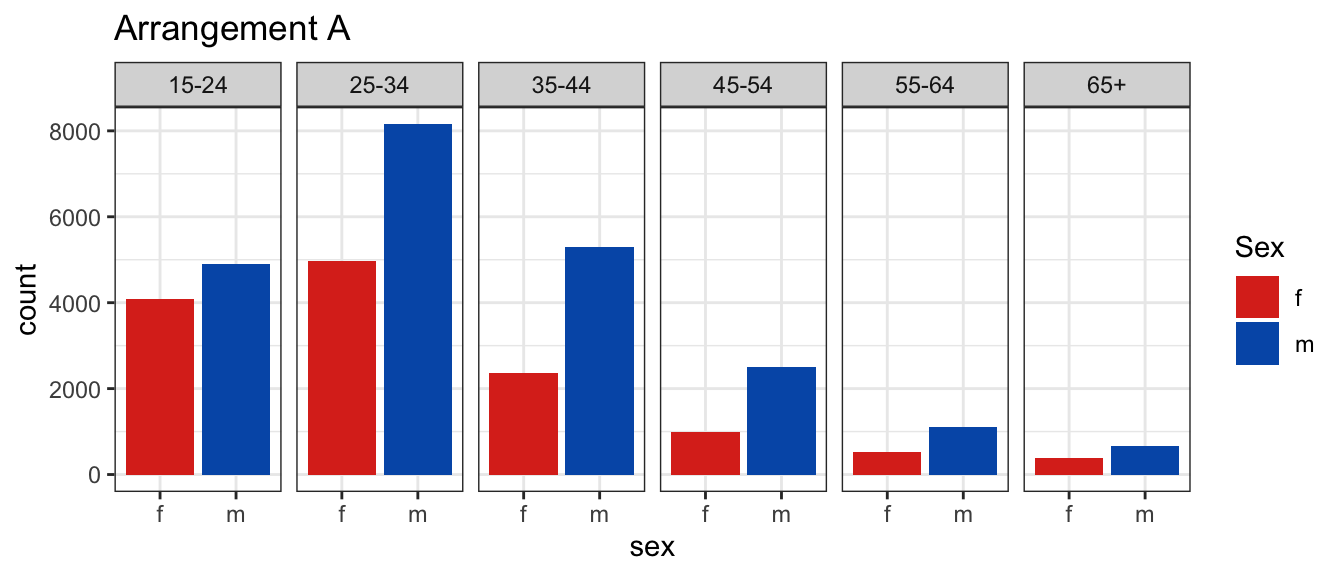
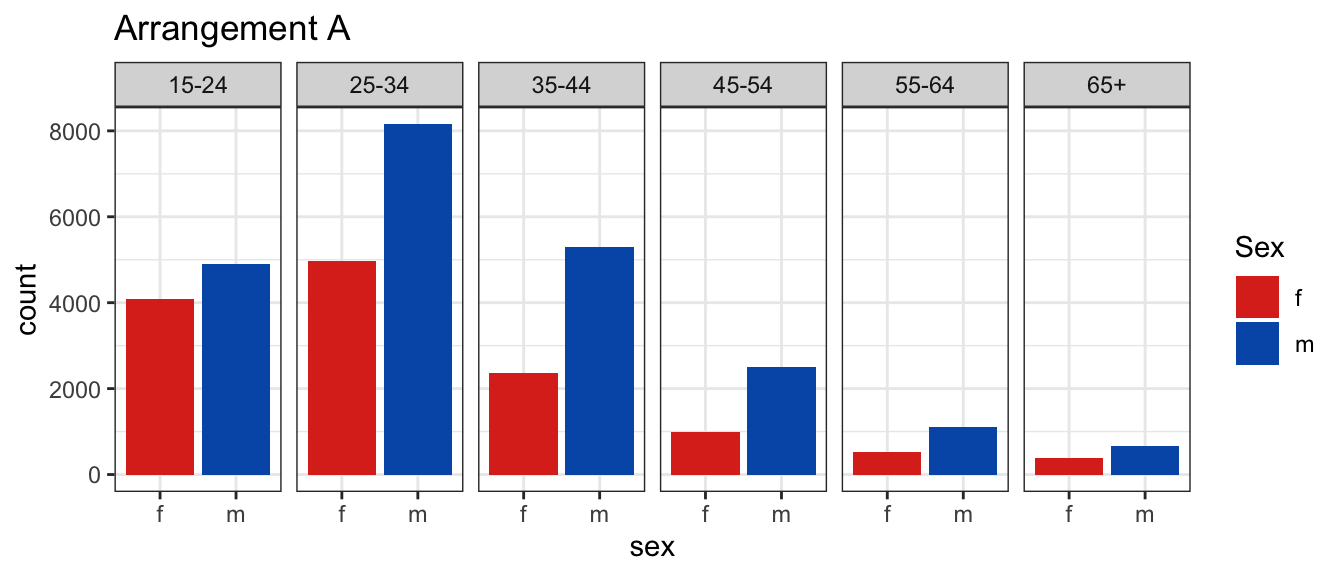
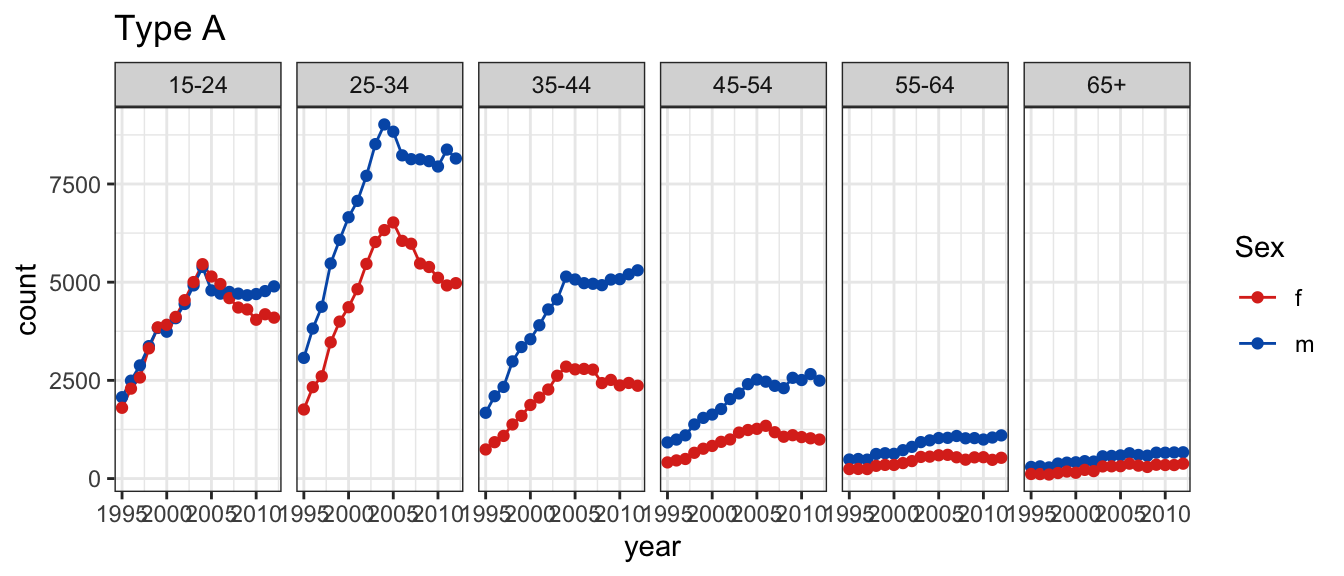
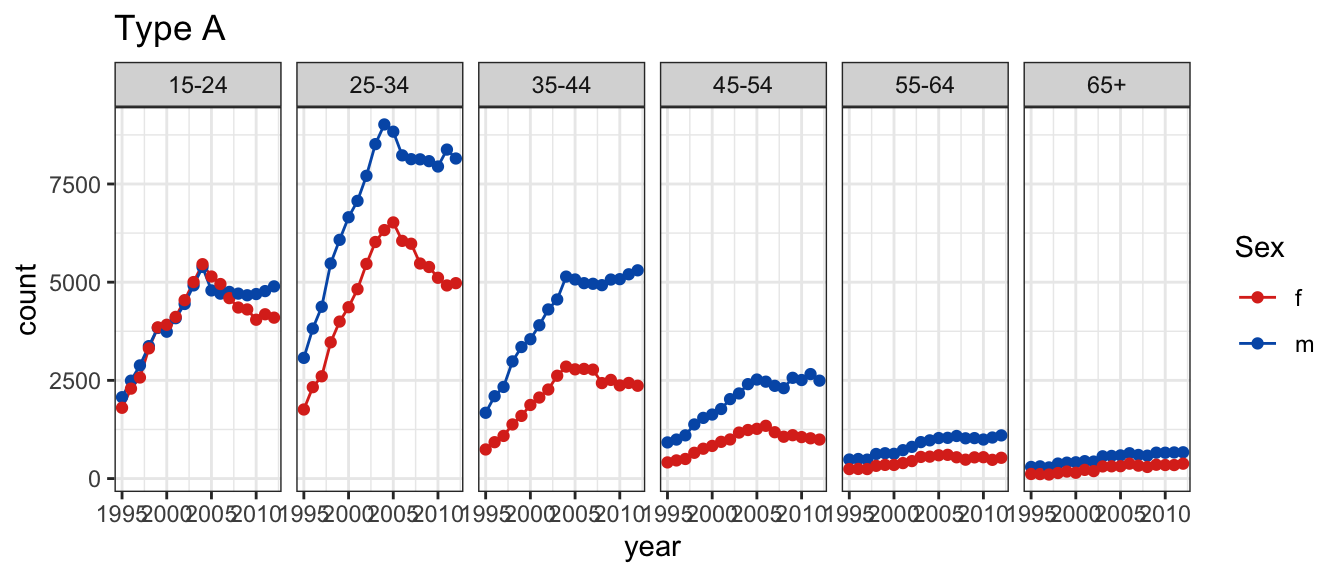
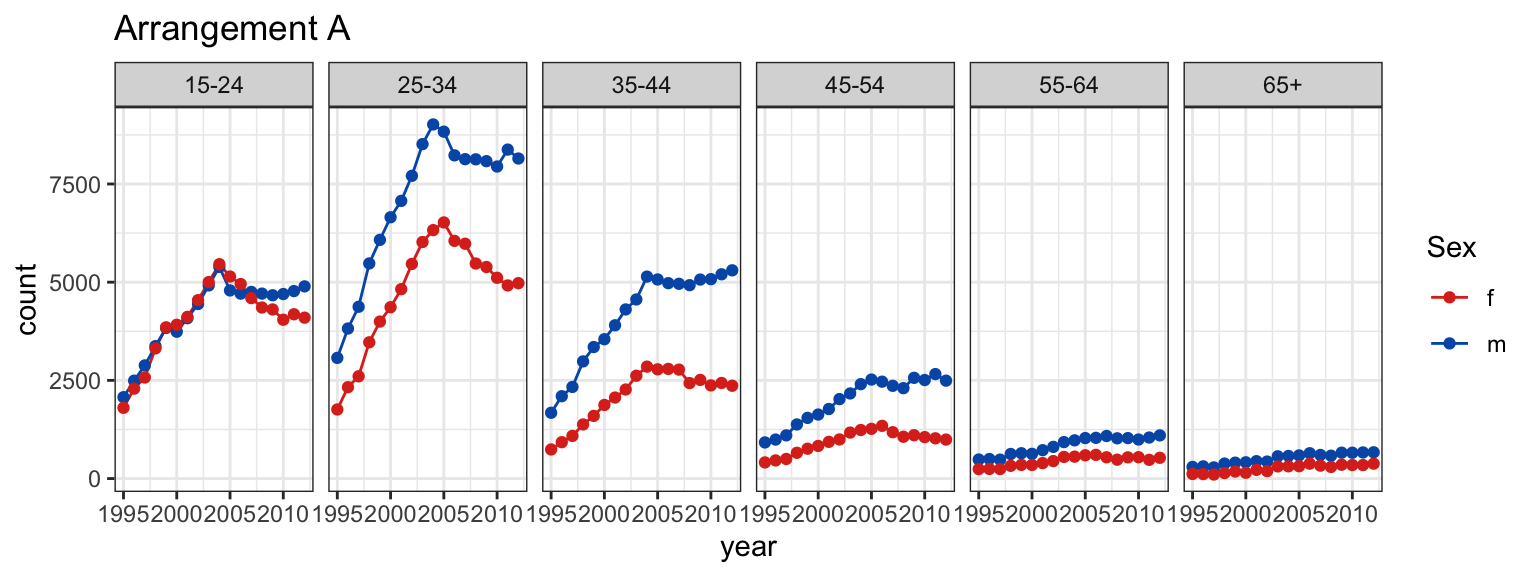
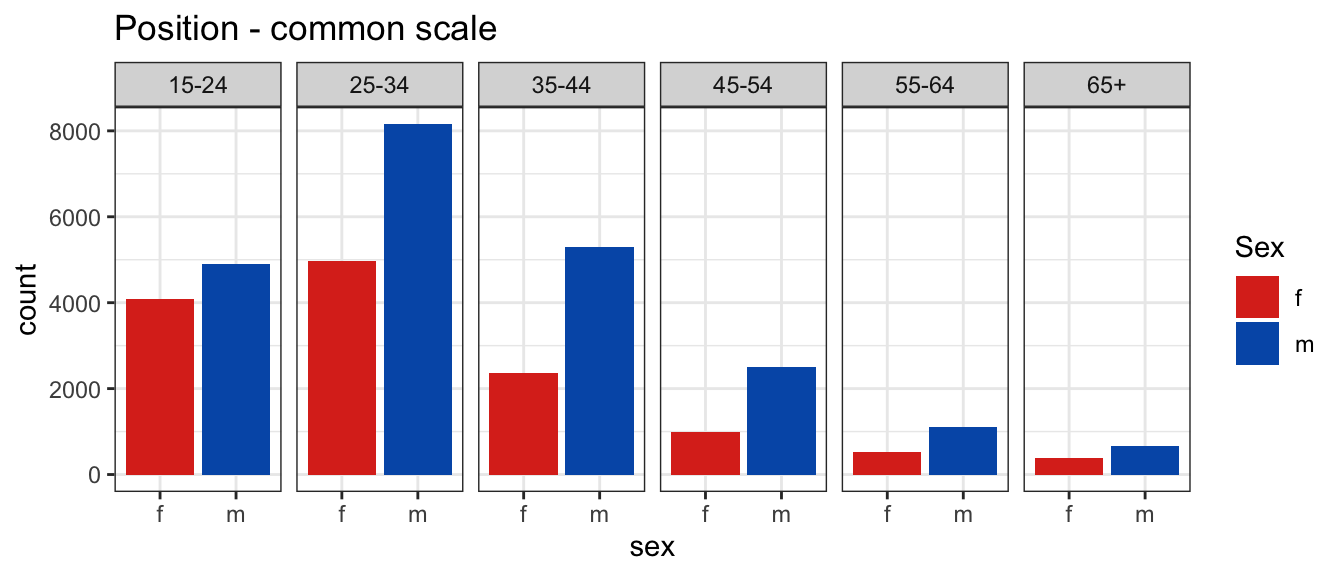
In arrangement A, separate plots are made for age, and sex is mapped to the x axis.
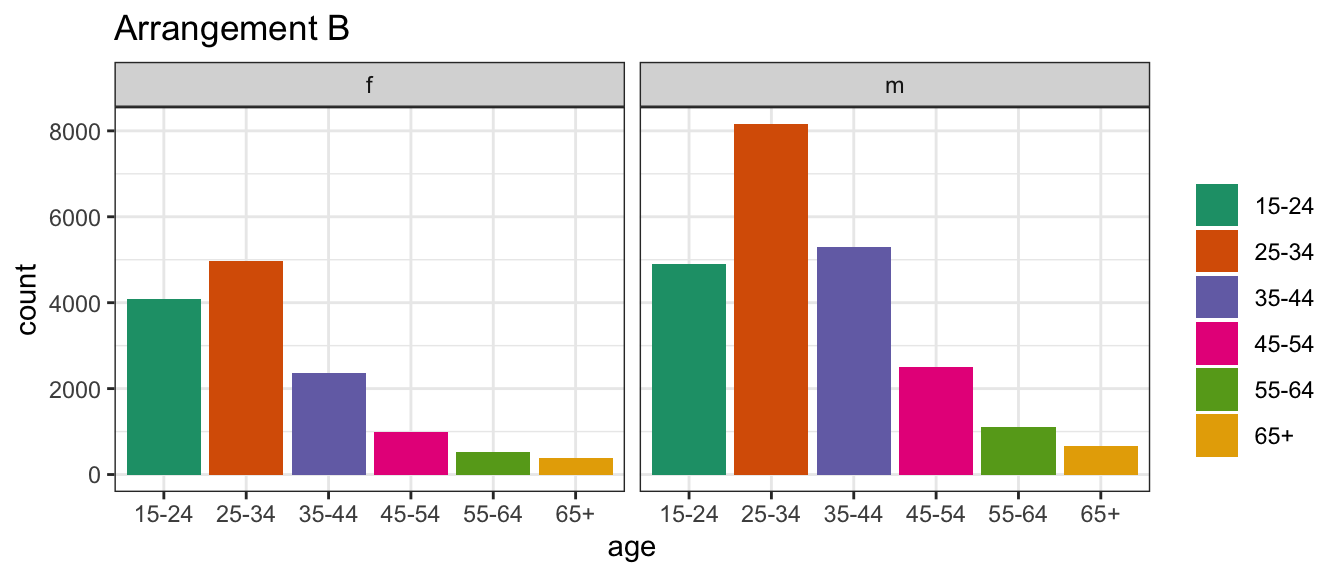
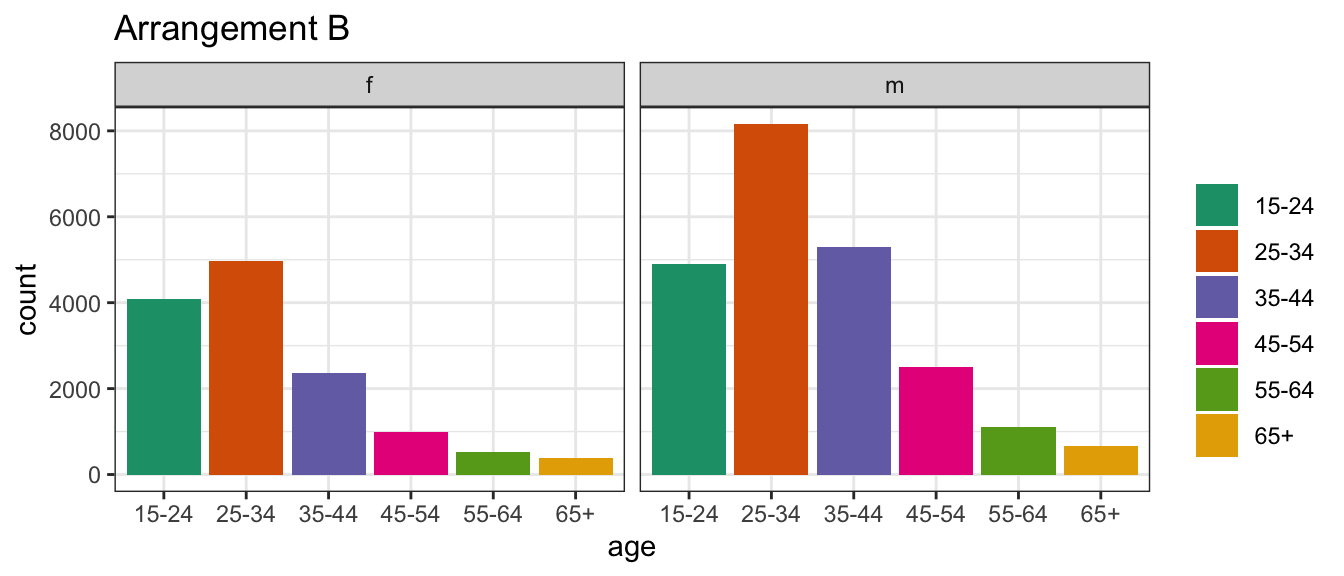
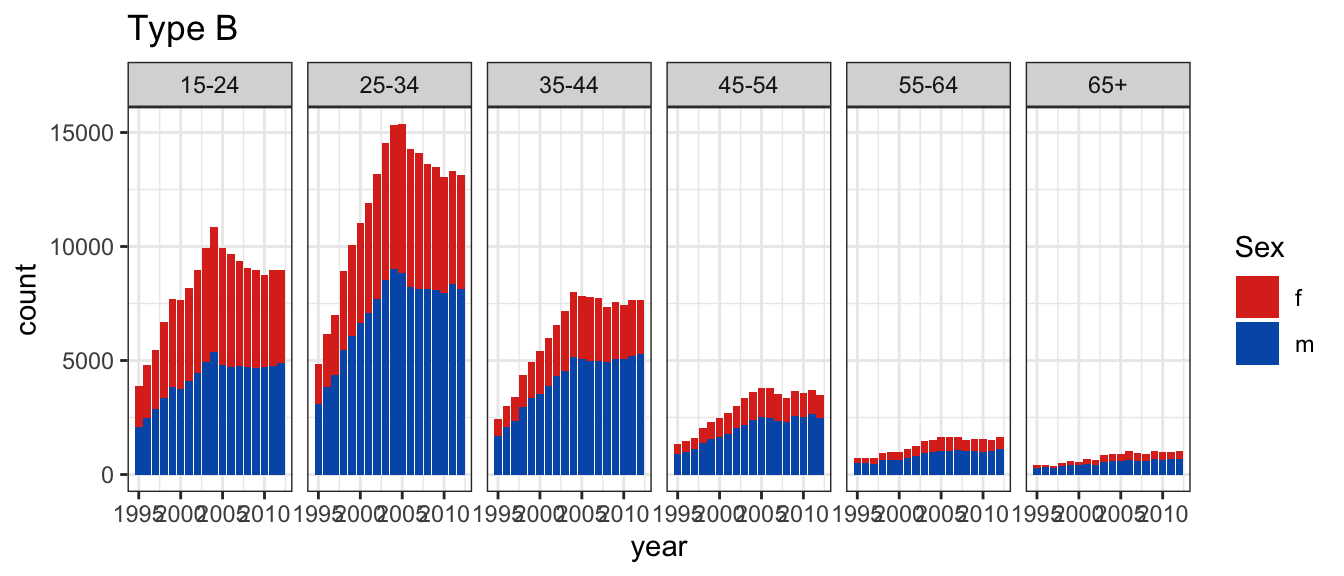
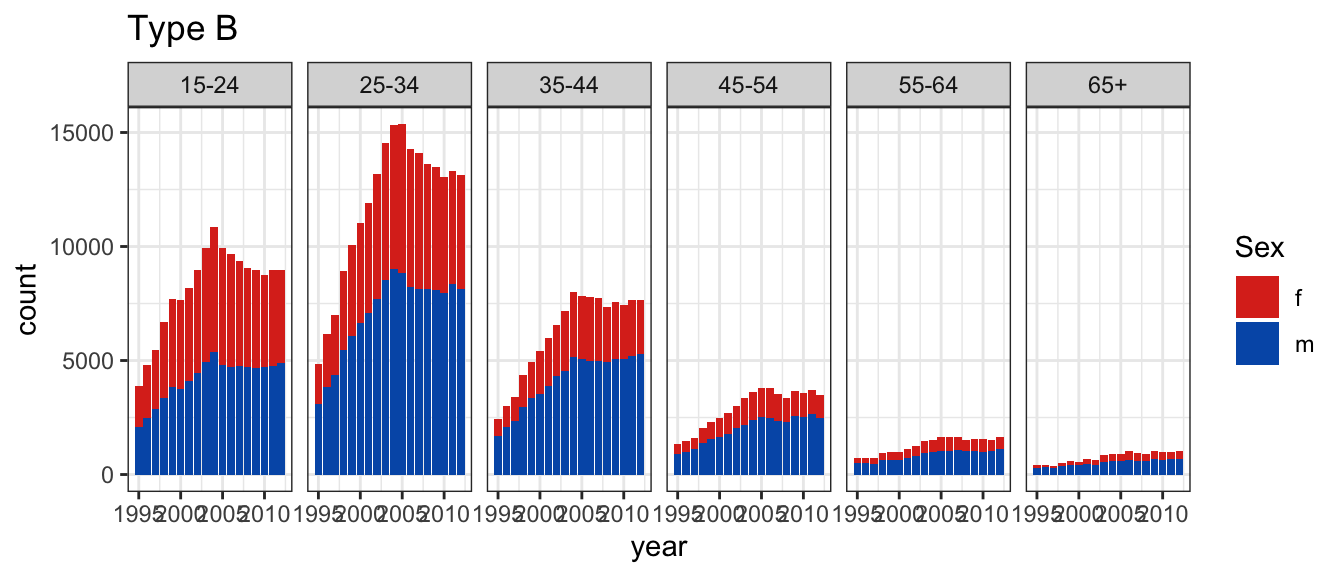
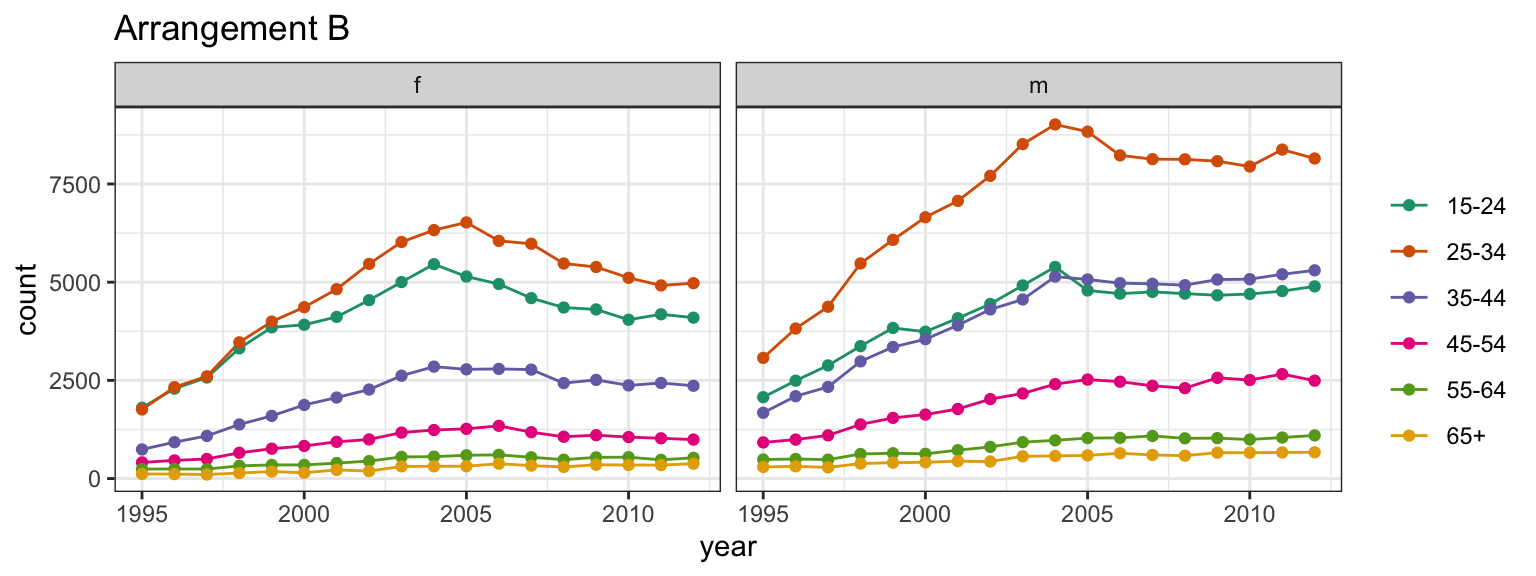
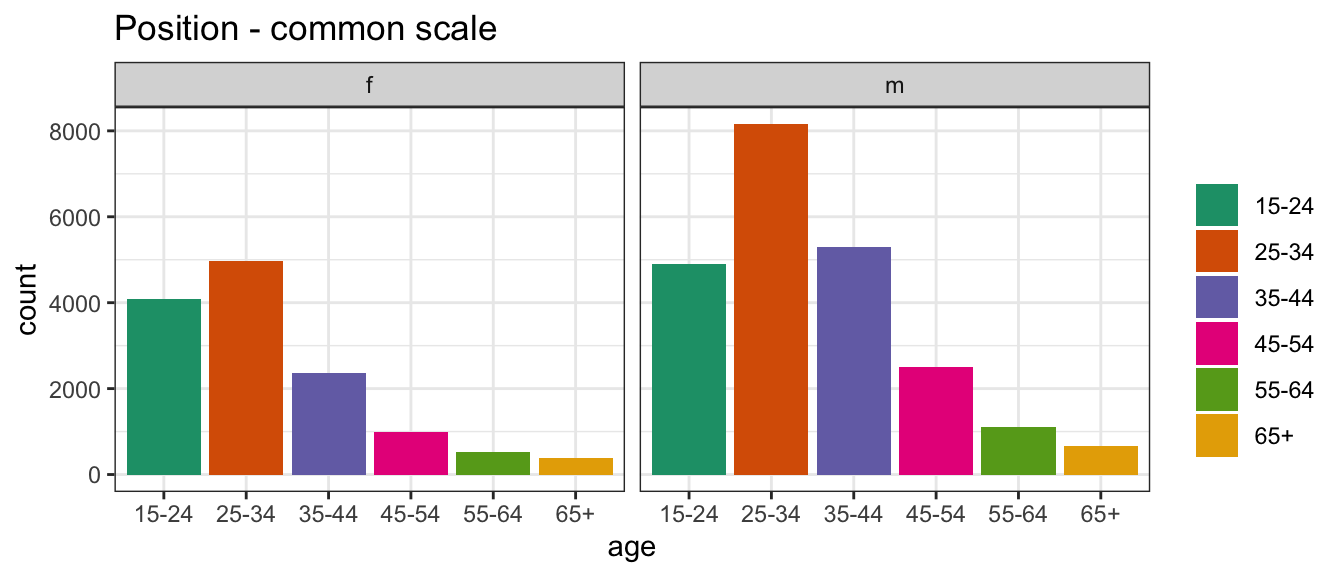
Conversely, in arrangement B, separate plots are made for sex, and age is mapped to the x axis.
At which age(s) are the counts for males and females relatively the same?
Which plot makes this question easier to answer?
We’re going to start out with an example of why perception and effective plot construction are related.
I will show you two different plots of the same data – newly diagnosed TB cases in Kenya in 2012 – with variables sex, age, and count (# diagnosed cases).
In the first plot, you’ll see facets for each age, with sex on the x-axis and count on the y-axis.
In the second plot, you’ll see separate facets for sex, with age on the x-axis and count on the y-axis.
Your goal is to figure out which plot is better for identifying which ages had approximately the same numbers of males and females diagnosed with TB.
Ready?
TWO MINUTE CHALLENGE 🔮 👽 👼
At which age(s) are the counts relatively similar across sex?
Which plot makes this easier? What do we learn from each? What’s the focus? What’s easy? What’s harder?
Take two minutes and answer the main question, but also think about what you might use each plot for, and what each plot’s focus is.
Arrangement A makes it easier to directly compare male and female counts, separately for each age group.
Generally, male counts are higher than female counts.
There is a big difference between counts in the 25-34 age group, and over 65 counts are almost the same.
Arrangement B makes it easier to directly compare counts by age group, separately, for females and males.
For females, incidence drops in the middle years much more strongly than it does for males.
TWO MINUTE CHALLENGE 🔮 👽 👼
Write out a question that would be easier to answer from arrangement B.
Go to www.menti.com and use the code 2979 2396.
What question would be easier to answer from arrangement B?
Three Variables
Next, we have two different plots of TB incidence in Kenya, based on three variables:
tb_kn |>select(year, sex, age, count) |>head(10)
# A tibble: 10 × 4
year sex age count
<dbl> <chr> <chr> <dbl>
1 1995 m 15-24 2072
2 1995 m 25-34 3073
3 1995 m 35-44 1675
4 1995 m 45-54 920
5 1995 m 55-64 485
6 1995 m 65+ 296
7 1995 f 15-24 1802
8 1995 f 25-34 1759
9 1995 f 35-44 741
10 1995 f 45-54 411
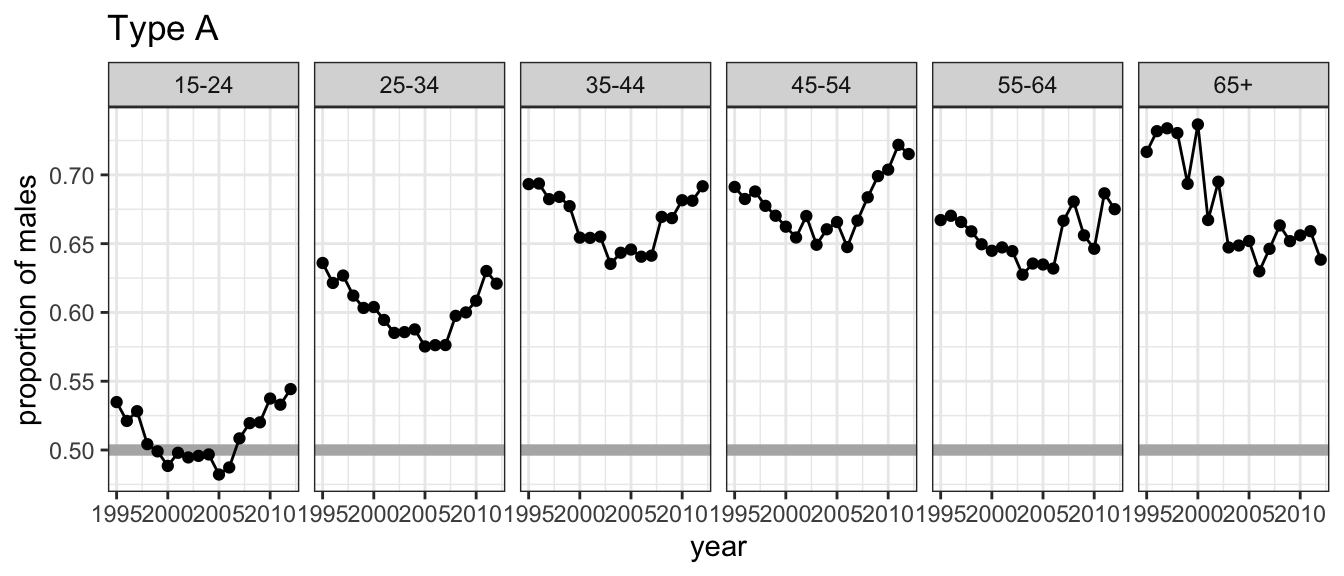
In plot type A, a line plot of counts is drawn separately by age and sex, and year is mapped to the x axis.
Conversely, in plot type B, counts for sex, and age are stacked into a bar chart, separately by age and sex, and year is mapped to the x axis
Is the trend for females generally decreasing over time? Which plot makes this easier?
Let’s make this just a bit harder by adding another variable - age.
We’ll have two plots again
the first plot will be a line chart, with facets by age and separate lines drawn for males and females.
the second plot will be a stacked bar chart, with facets by age. The counts for females will be shown on top of the counts for males.
Your goal is to determine which chart makes it easier to identify the direction of the trend for females.
You’ll have about two minutes.
TWO MINUTE CHALLENGE 🔮 👽 👼
Which type of plot makes it easier to answer
Is the trend for females generally decreasing over time?
Plot type A makes it easier to examine trend for each group.
This plot should probably have used 0 as the lower limit.
Plot type B is really only allowing the overall trend in count to be examined separately by age.
It is possible to see trend for males.
Trend for females is buried because the bars start at irregular heights.
The separated bars distract a bit from digesting the overall count.
TWO MINUTE CHALLENGE 🔮 👽 👼
What are the pros and cons of each way of displaying the same information? Should specific limits on axes be made?
Should the limits of the y axis in plot A include 0 (zero)?
Plot type A makes it easier to examine trend for each group.
This plot should probably have used 0 as the lower limit.
Because plot B shows bars, 0 is automatically included.
It might be helpful to have plot B with different scales by facet, if our goal is to be able to see any trend at all for older age groups.
This would be useful alongside the plot with the same axes for all facets, not instead of that plot.
TWO MINUTE CHALLENGE 🔮 👽 👼
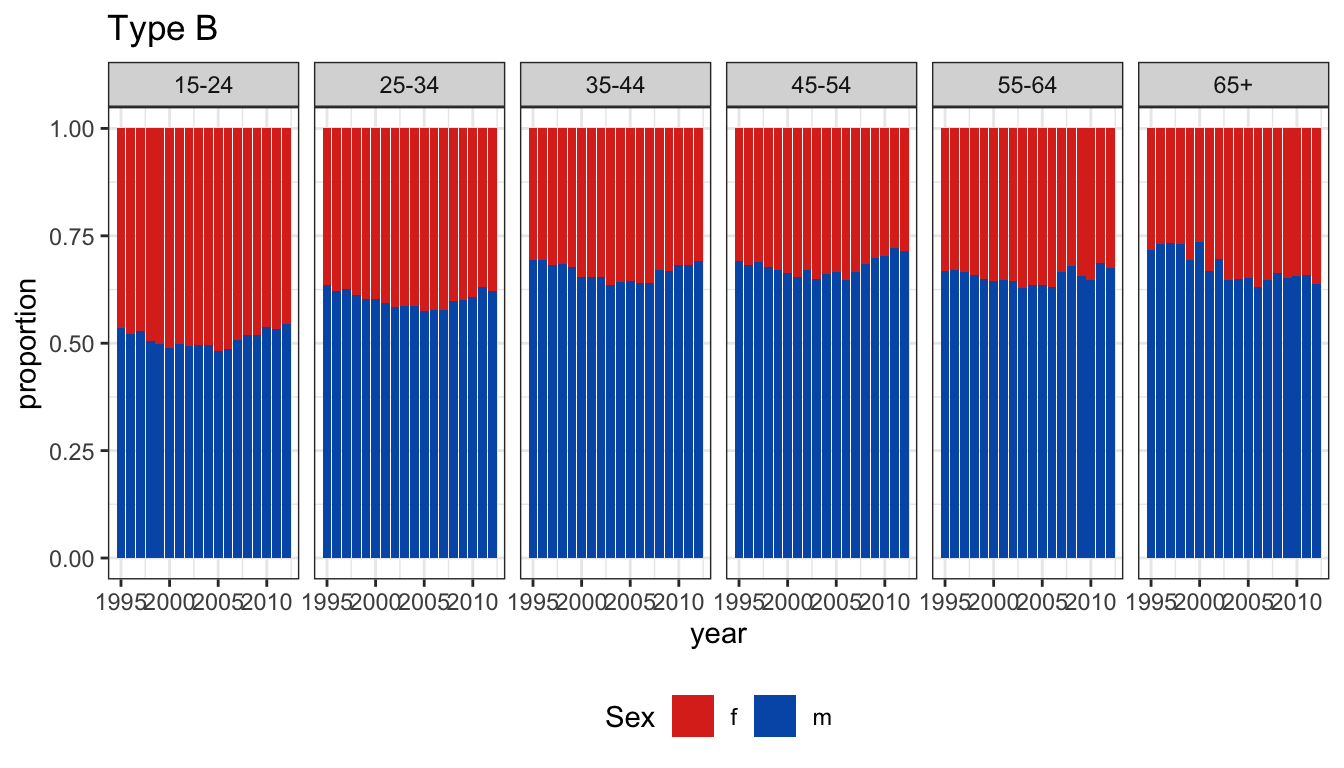
Plot A shows the proportion as a line plot.
Plot B shows stacked bars scaled to 100% for females and males.
Is there an age effect in the proportion of incidence by gender? Is there a temporal trend in the proportions?
Plot A makes it easier to examine the trend in proportion.
It is easy to miss that all the proportions are greater than 0.5, despite having a guideline (grey) at 0.5.
It could be argued that setting the vertical axis limits could alleviate this.
The fluctuations from year to year are more visible.
Maybe adding a trend model could be helpful, to reduce this noise.
Without colour, the plot is less visually appealing.
Plot B makes it easier to see that the proportion for males is almost always higher than for females.
It also suggests that there is a very minor temporal trend, because the small fluctuations between years is less visible.
Having colour makes it more visually appealing.
There is less data processing.
Perceptual principles
Hierarchy of mappings
Pre-attentive: some elements are noticed before you even realise it.
Color palettes: qualitative, sequential, diverging.
Proximity: Place elements for primary comparison close together.
Change blindness: When focus is interrupted differences may not be noticed.
In the plots we just discussed, there were several perceptual principles at play:
There is a hierarchy of mappings between variables and geometric objects
Perception happens in a sequence: some things are perceived without attention, and others require attention and intentional focus.
Color palettes (or lack thereof) can make a big difference in how we perceive the data!
It’s helpful to have things we want to compare next to each other – proximity matters
If we have to pivot between different facets of a chart, it’s harder to see any differences in the data
Hierarchy of mappings
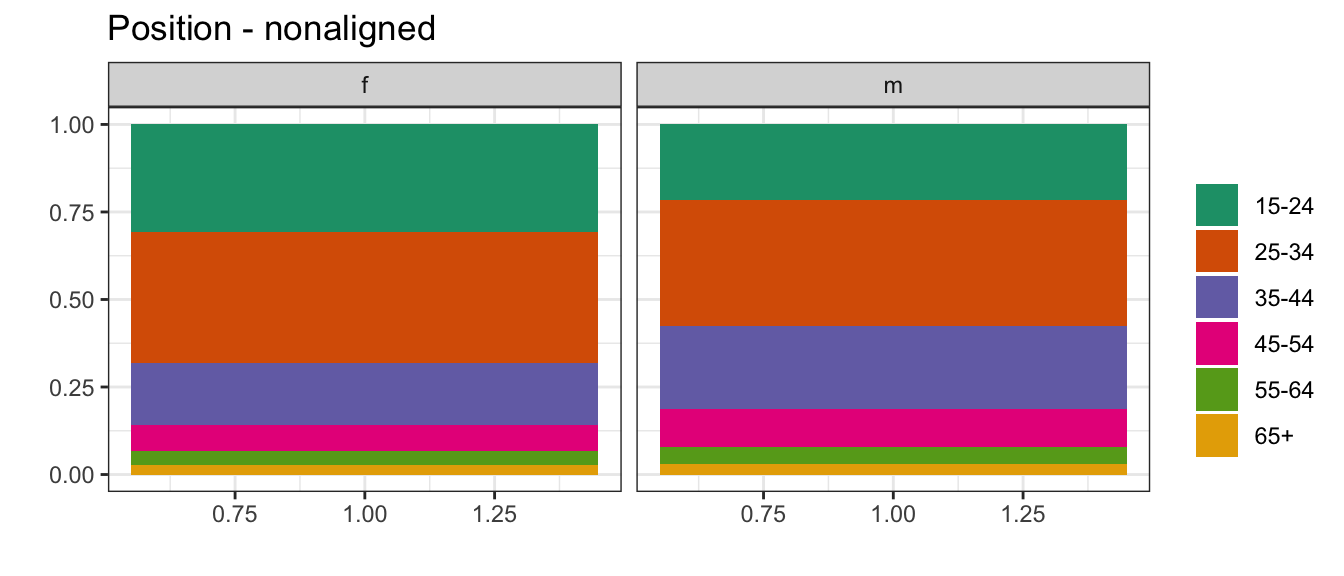
Position - common scale (BEST)
Position - nonaligned scale
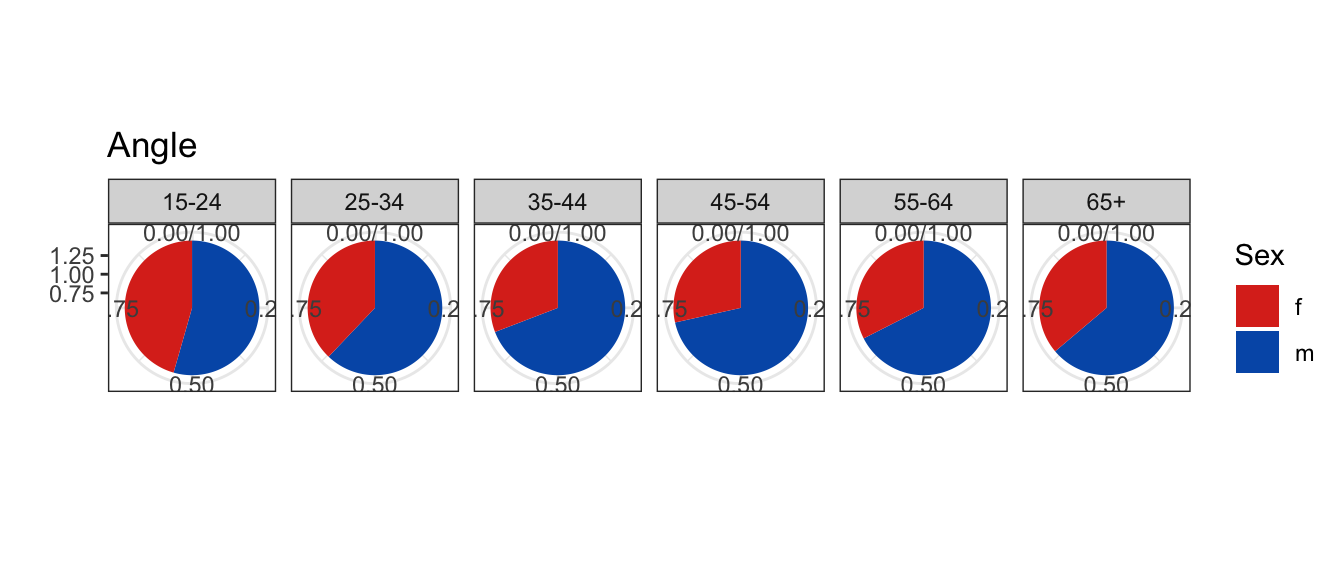
Length, direction, angle
Area
Volume, curvature
Shading, color (WORST)
(Cleveland, 1984; Heer and Bostock, 2009)
The hierarchy of mappings is drawn primarily from research by Cleveland & McGill in the 1980s on basic perception.
It’s important to know that this hierarchy applies to estimation accuracy, but not necessarily to speed, accuracy of the “gist” of the plot, or relative magnitude judgments.
It’s much easier to compare aligned quantities – think of two bars placed next to each other, where the bottom is aligned to the axis - you’re essentially just comparing the position of the top of the bar. When the bars are no longer aligned, as in a stacked bar chart, it’s a bit harder to estimate the size of the bar correctly – this is one example of a nonaligned scale; another would be making comparisons between facets that don’t share a scale.
Then comes a 3-way tie between length, angle, and direction – these are easy enough to see, but not as easy to estimate the magnitude.
As we increase the dimensionality of the geometric object, we lose accuracy – area is less accurate than length, and volume is less accurate than area. This is one really good reason not to add extra dimensions to your bar charts (looking at you, MS Excel!)
Finally, we have color and shading. Remember, this is for estimation accuracy – color and shading are both useful, but it’s much harder to get an exact numerical estimate from the legend. Sometimes, people add a third dimension to a plot using color, and this hierarchy should tell you that if you’re going to do that, you want to use the least important numerical variable to show using color… save the important ones for the \(x\) and \(y\) axes, which use position.
TWO MINUTE CHALLENGE 🔮 👽 👼
Come up with a plot type for each of the mappings.
Position - common scale (BEST)
Position - nonaligned scale
Length, direction, angle
Area
Volume, curvature
Shading, color (WORST)
(Cleveland, 1984; Heer and Bostock, 2009)
Take a couple of minutes and come up with a chart that uses each type of mapping
scatterplot, barchart
side-by-side boxplot, stacked barchart
piechart, rose plot, gauge plot, donut, wind direction map, starplot
Next, we should talk about color – when to use it, what type of scale you should use for different types of variables, and how to ensure that your audience can perceive your color scale.
The colorbrewer project is helpful, because it provides some useful scales as well as attributes for those scales. It’s good to realize that these attributes apply to maps – they may work well enough for other types of charts, but they may not. Everything has limitations.
Colorbrewer helpfully divides their palettes into different types:
Sequential, a scale that increases the saturation (amount of color) to show magnitude
Diverging, a scale that has two directions of saturation, shown using different hues. This type of scale is useful for showing e.g. temperature, deviation from the mean, etc., where the direction is just as relevant as the value.
Qualitative scales are used for categorical variables. With qualitative scales, it’s important to keep the number of categories low enough that we can remember what color matches what value.
Quantitative values should be mapped to a directional scale indicating high or low – which direction will depend on what is important for your data.
If you want to use a quantitative scheme that is multi-hued, you can use the viridis palette to do so: the schemes in that package will reduce to greyscale in black and white – as a result, they also happen to be much more safe for colorblind people.
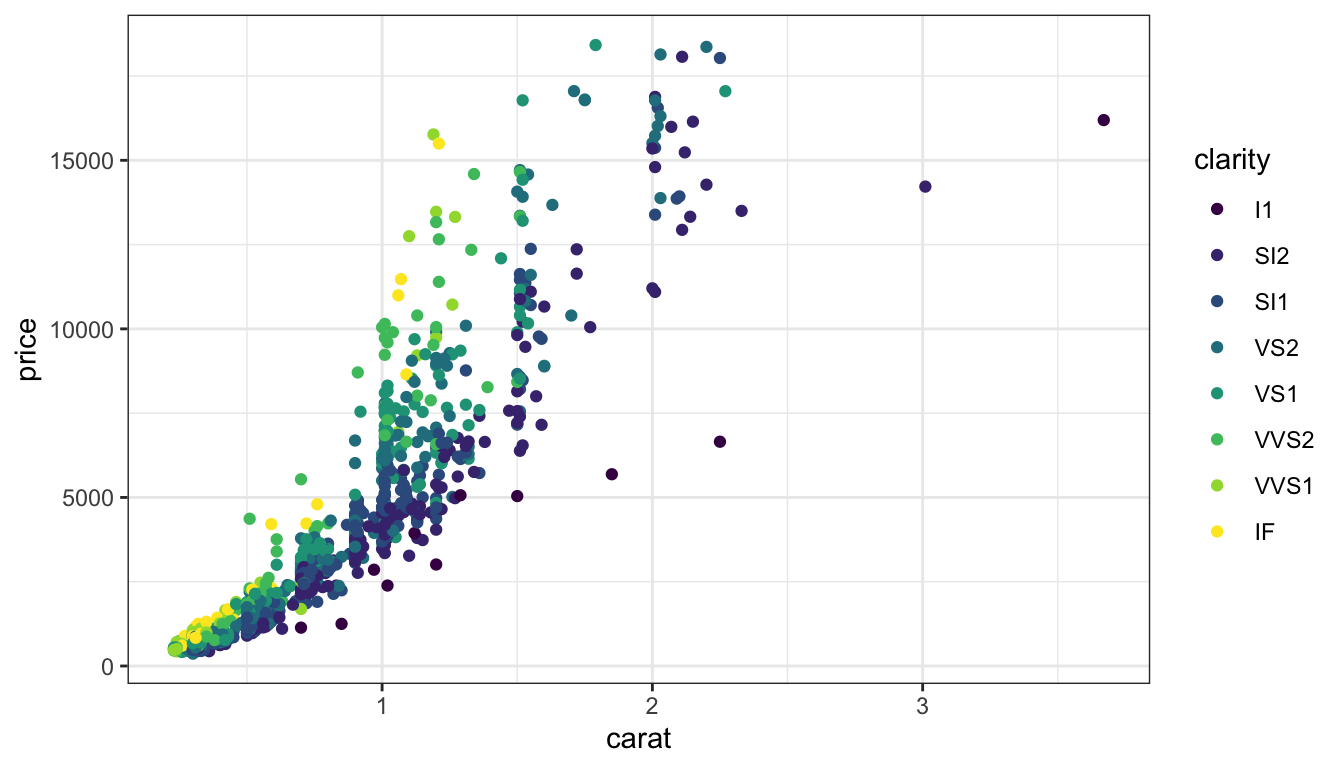
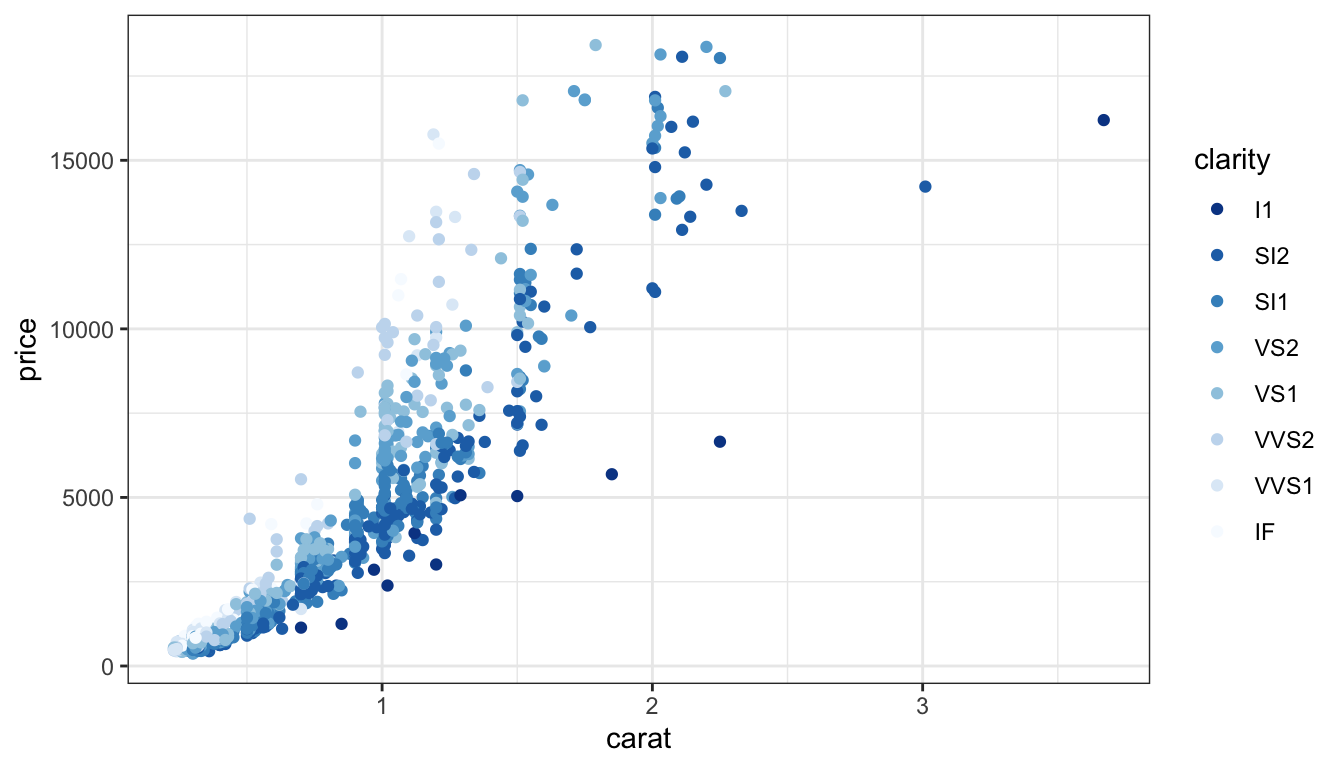
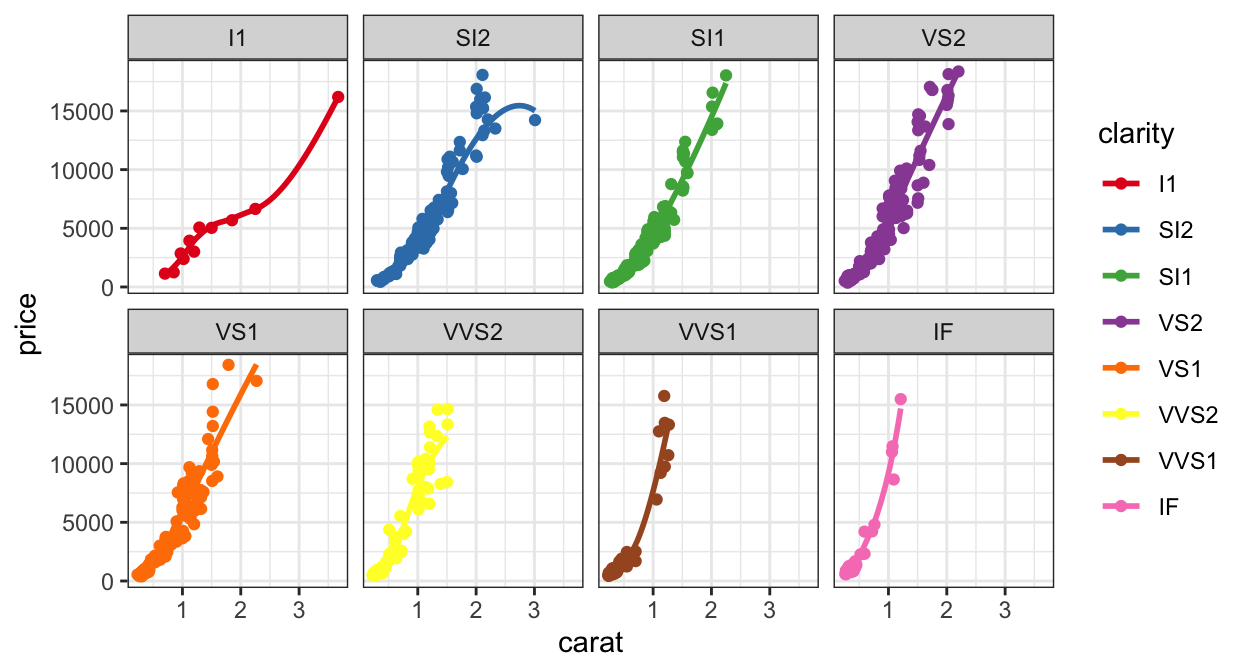
In this case, we have an ordered categorical variable mapped to color – clarity. The categories are ordered according to the clarity of the stone, with I1 being worst and IF being best.
Sequential
d +scale_colour_brewer(direction =-1)
Default brewer sequential scale, blues.
Focus is on the dark blue.
Quantitative values should be mapped to a directional scale indicating high or low – which direction will depend on what is important for your data.
Here, I’ve mapped the dark blue to the lower clarity, with the idea that clear and white are similar. This does put the focus on the lower-clarity diamonds, though.
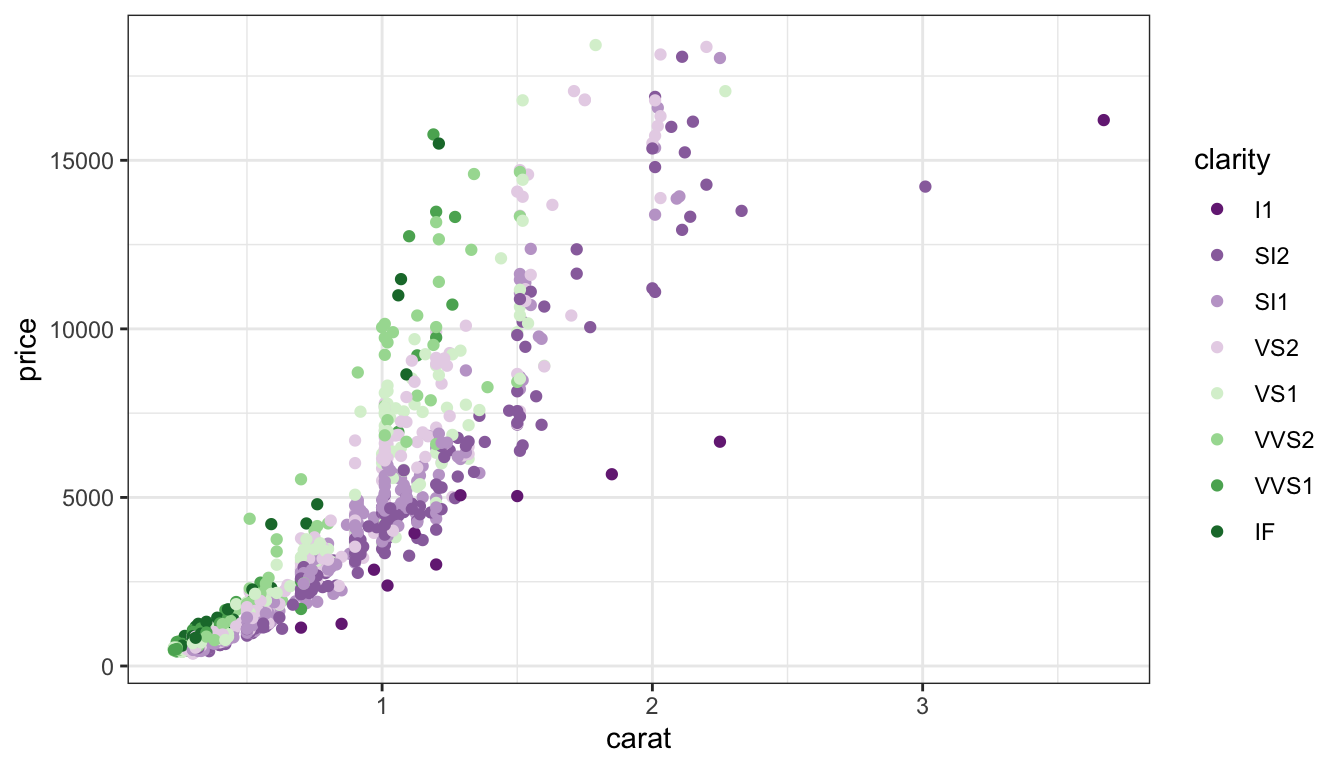
Diverging
d +scale_colour_brewer(palette="PRGn")
Emphasize both ends, high AND low
De-emphasize middle
If we want to put the focus on both ends of the spectrum, we can use a diverging scale, like this purple-green scale.
When you use a diverging scale, the safest is actually purple to orange through a very light color like white – this is accessible to all major types of colorblindness.
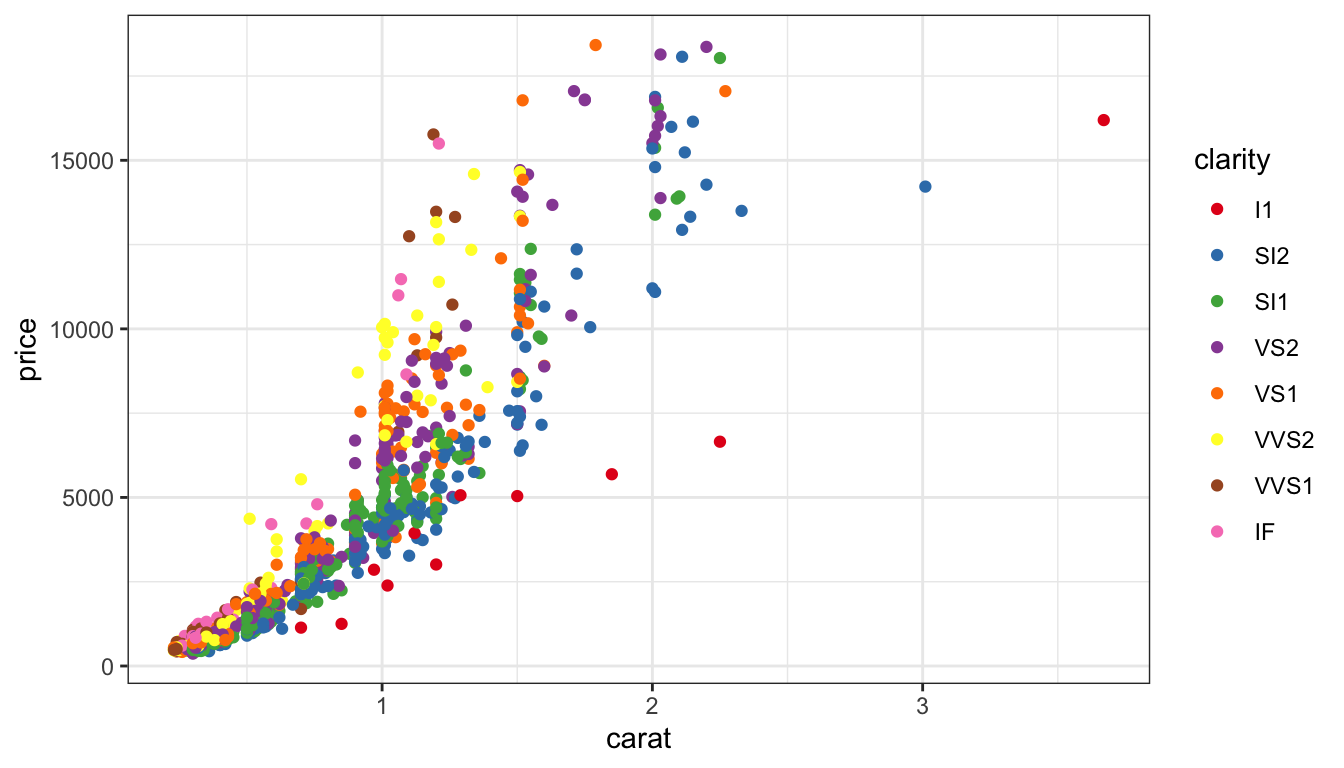
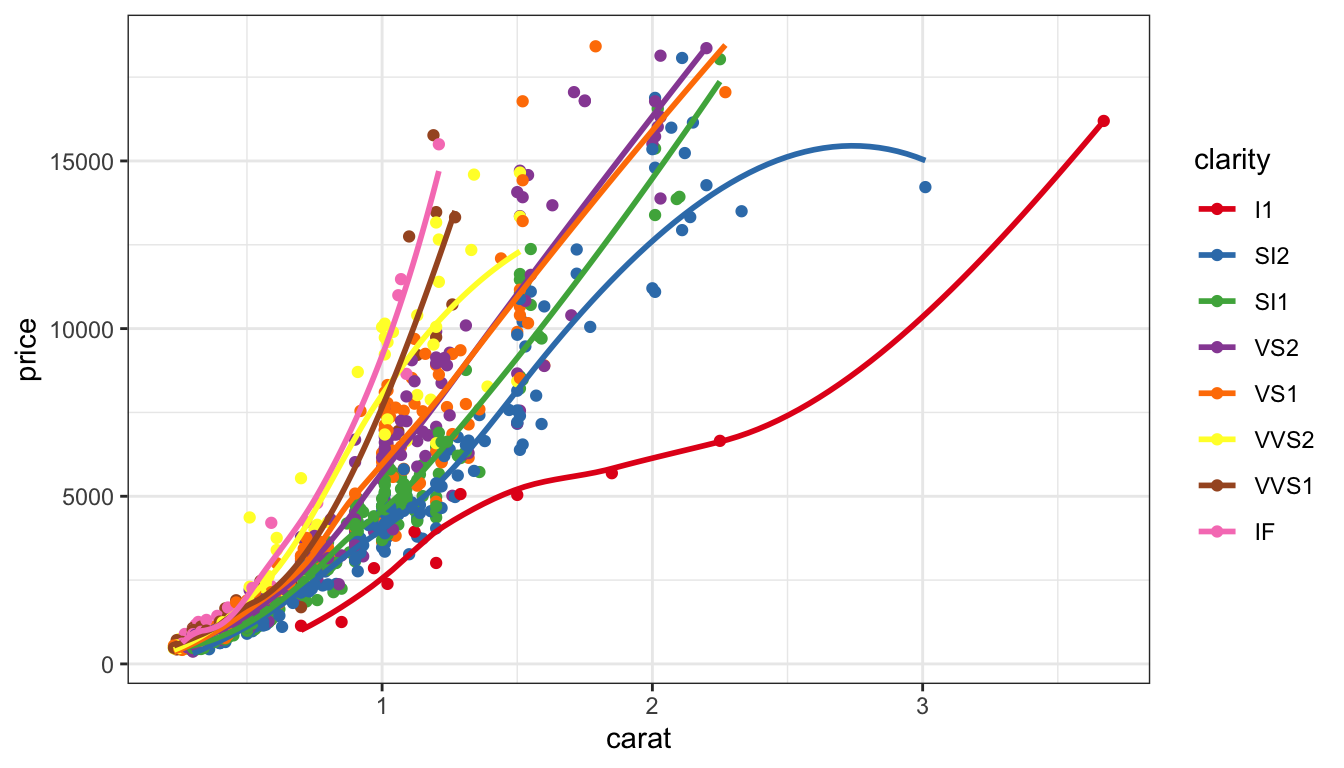
Qualitative
d +scale_colour_brewer(palette="Set1")
Map qualitative variables to most differentiated set of colors.
It’s possible to have too many colours to perceive differences.
Your working memory is limited to 7 plus-or-minus 2 items - between 5 and 9 things. You run up against this when you try to remember a phone number after looking it up but before typing it in – an unfamiliar area code can really make that task difficult because it puts you up to 10 items to remember.
When we have more than 9 categories, it makes it hard to remember what color corresponds to what value… it can also make the legend really big. It can be helpful to have an “other” category that you group smaller values into, if you’re mostly interested in the main categories.
TWO MINUTE CHALLENGE 🔮 👽 👼
Of the previous four colour schemes on the same data, which would be the most appropriate? Why?
Online checking tool coblis: upload an image and it will re-map the colors for different colour perception issues.
The package colorblind has color blind friendly palettes (Susan: but the colours are awful 😭).
There are colorblindness simulators, but I’ve never found one that actually matches what I see, because there are many different mutations that can cause color deficiency, and so it exists along a spectrum for each of the 3 cones we have.
Roughly 5% of the population (10% of men, 0.2% of women) are colorblind.
The viridis package claims to be colorblind friendly. The colorblind package has some color deficiency friendly palettes, but they can be a bit ugly.
Whatever route you go, the safest way to make something colorblind-friendly is to make it so you could show it in greyscale with no issues. This also helps with publishing and not having to pay for color figures, as well as lowering printing costs in the office if you are working with hard copies.
Color blind Simulation
Original colours
Color blind view
This is what the default discrete color scale in ggplot2 apparently looks like if you do not have a functioning green cone. Not so great, right? You can basically see direction but not much more.
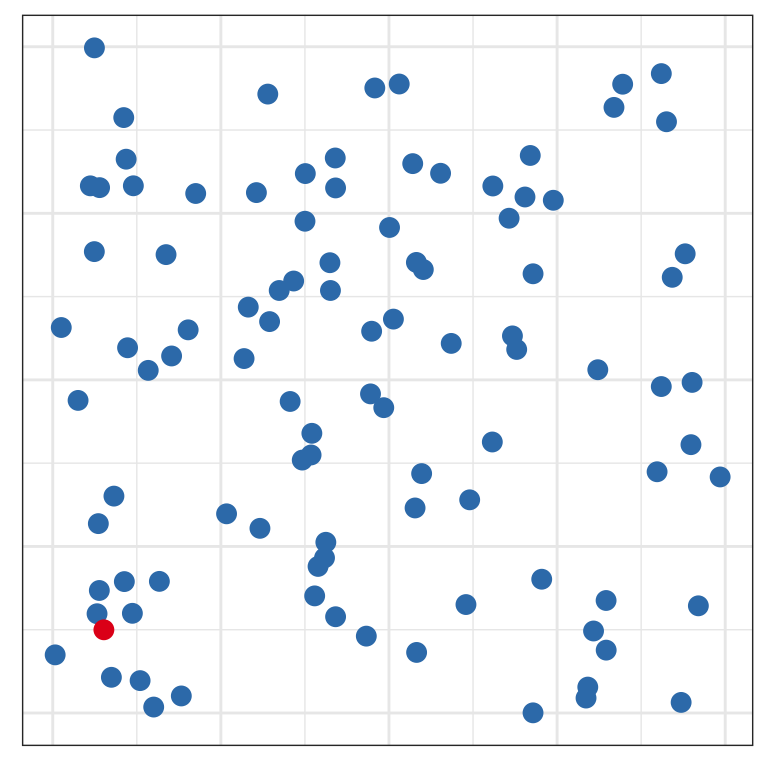
Pre-attentive
Can you find the odd one out?
Pre-attentive
Is it easier now?
Some features, like shape and color, are processed pre-attentively - you don’t have to look at every point to see which one doesn’t match. This is parallel processing at work, and when you can take advantage of it, you should.
A combination of pre-attentive features that are used to encode different variables must be processed serially – you have to look at each point separately. So make sure you take advantage of this, but don’t get greedy!
Dual-encoding points by using both shape and color to show the same variable can make your plots more accessible and easier to read.
Proximity
Place elements that you want to compare close to each other. If there are multiple comparisons to make, you need to decide which one is most important.
Earlier, we demonstrated the importance of proximity for making comparisons – when you design your chart, put the most important things close to each other so that they’re easy to compare. If you want the viewer to compare sex effects, then use arrangement A. If it’s more important for the viewer to compare age effects, use B.
You do have to pick, but you can also make multiple charts to illustrate different aspects of the data.
Mapping and proximity
Same proximity is used, but different geoms.
Which is better to determine the relative ratios of males to females by age?
Geom is also important. Which plot works better for showing relative ratios of male/female for each age group?
We could probably achieve the same effect by using a stacked bar chart – pie charts use angle or area, while stacked bars use length.
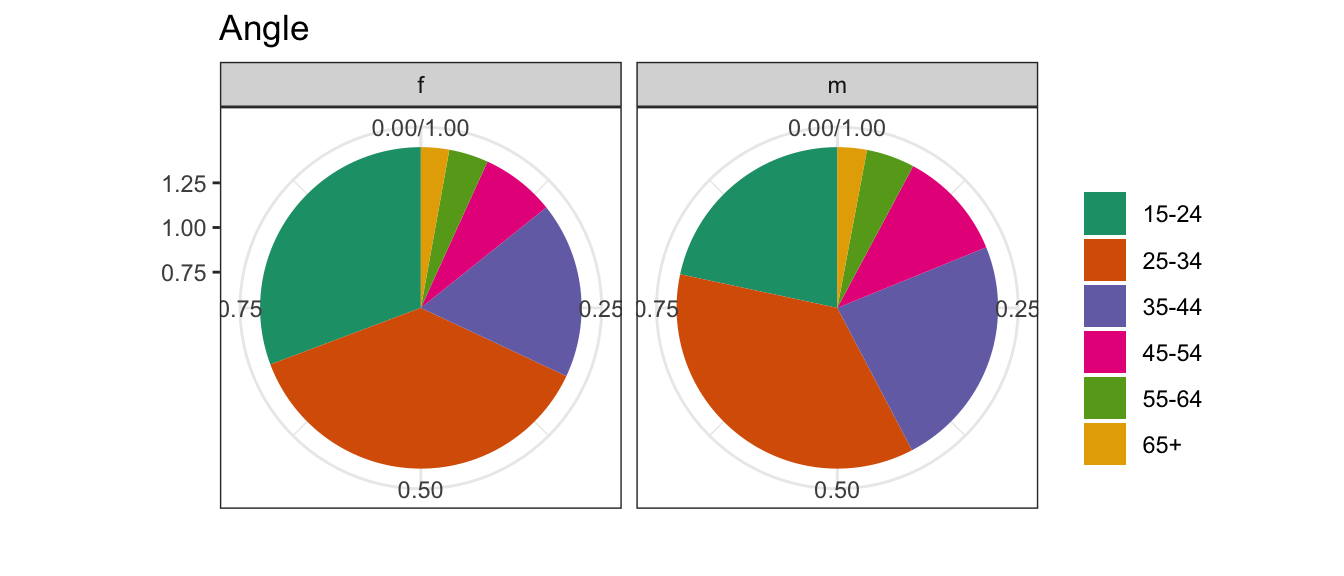
Mapping and proximity
Same proximity is used, but different geoms.
Which is better to determine the relative ratios of ages by sex?
While pie charts can be useful when there are just 2 categories, that advantage disappears very quickly when the number of categories increases. Once you need to compare more than 3 categories, a stacked (or not stacked) bar chart will provide a better comparison.
When you have to move around the chart and aren’t making side-by-side comparisons, it gets pretty hard to see differences!
This is what we mean by change blindness.
It’s much easier to see that the purple line is more shallow.
Core principles
Make a plot of your data!
The hierarchy matters if the structure is weak or differences b/w groups are small.
Knowing how to use proximity is a valuable and rare skill
Use of colour: don’t over use
Too many colours
Mapping cts variable to colour to add another dimension
Core principles
Show the data!
Statistics are good if there’s too much data
Always plot the data for yourself to see the variability
One plot is never enough
Plot the data in different ways
Understand the relationships between variables
Your turn
This builds on the exercise from the previous session.
Using your choice of country, for example, Australia, make a set of plots to explore the TB incidence among males relative to females over different age groups for 2012.
Choose your best plot to answer this question: Is there a higher prevalence of TB among younger women in 2012?