In this protocol the plot of the real data is embedded amongst a field of plots of data generated to be consistent with some null hypothesis. If the observe can pick the real data as different from the others, this lends weight to the statistical significance of the structure in the plot. The protocol is described in Buja, Cook, Hofmann, Lawrence, Lee, Swayne, Wickham (2009) Statistical inference for exploratory data analysis and model diagnostics, Phil. Trans. R. Soc. A, 367, 4361-4383.
lineup(method, true = NULL, n = 20, pos = sample(n, 1), samples = NULL)Arguments
- method
method for generating null data sets
- true
true data set. If
NULL,find_plot_datawill attempt to extract it from the current ggplot2 plot.- n
total number of samples to generate (including true data)
- pos
position of true data. Leave missing to pick position at random. Encryped position will be printed on the command line,
decryptto understand.- samples
samples generated under the null hypothesis. Only specify this if you don't want lineup to generate the data for you.
Details
Generate n - 1 null datasets and randomly position the true data. If you pick the real data as being noticeably different, then you have formally established that it is different to with p-value 1/n.
Examples
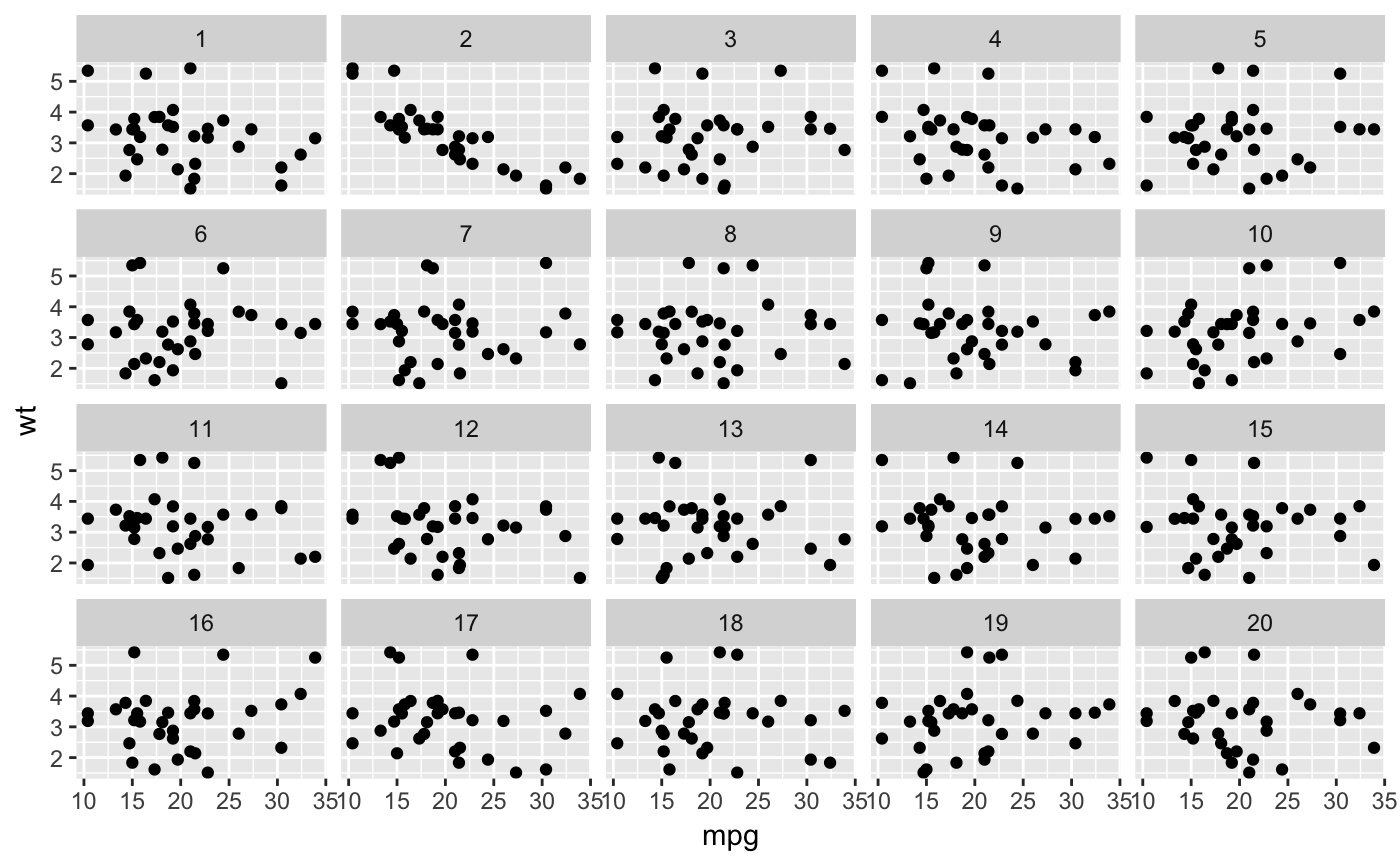
library(ggplot2)
ggplot(lineup(null_permute('mpg'), mtcars), aes(mpg, wt)) +
geom_point() +
facet_wrap(~ .sample)
#> decrypt("gwqp 2J5J c0 t8Zc5c80 dA")
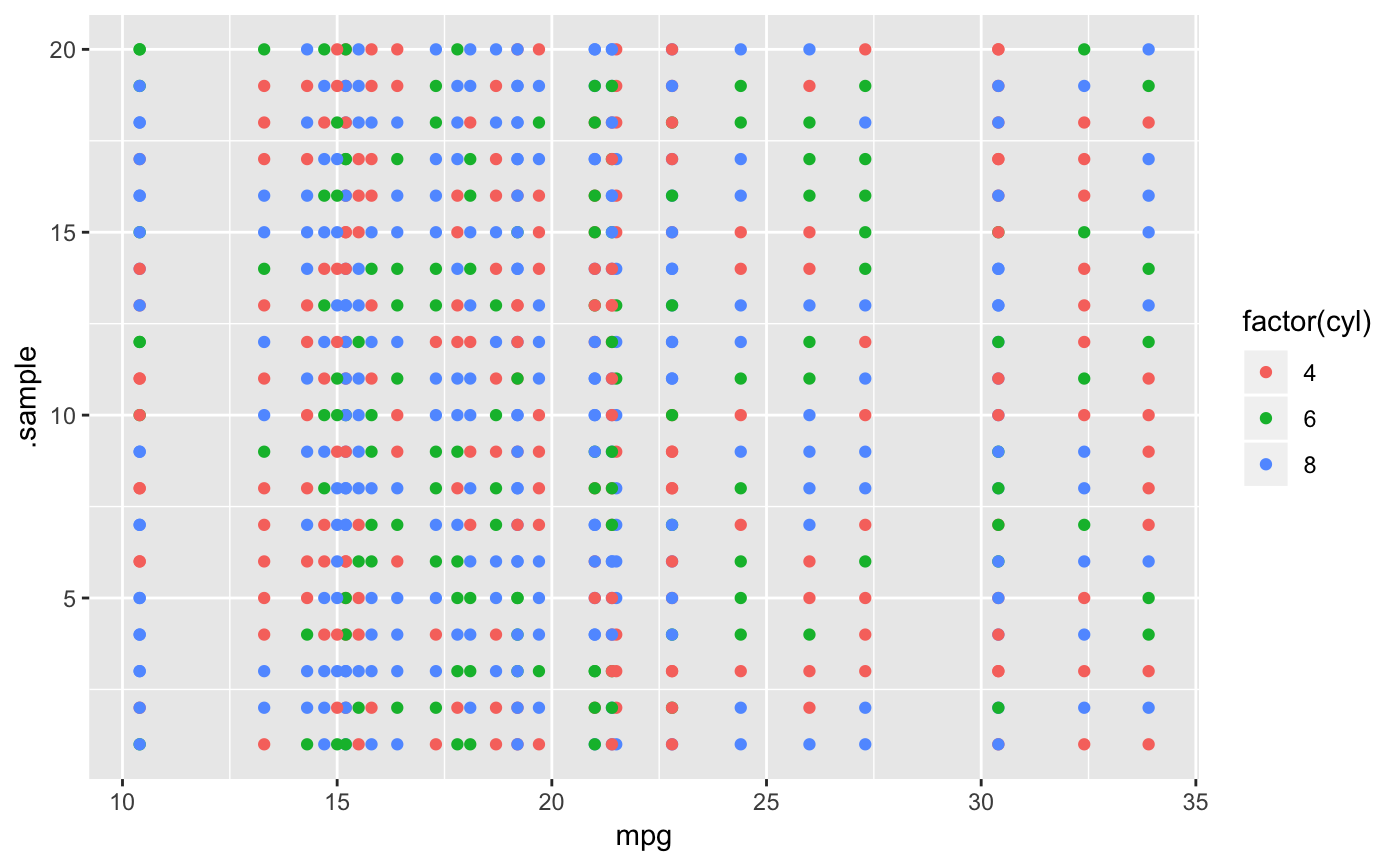
 ggplot(lineup(null_permute('cyl'), mtcars),
aes(mpg, .sample, colour = factor(cyl))) +
geom_point()
#> decrypt("gwqp 2J5J c0 t8Zc5c80 Am")
ggplot(lineup(null_permute('cyl'), mtcars),
aes(mpg, .sample, colour = factor(cyl))) +
geom_point()
#> decrypt("gwqp 2J5J c0 t8Zc5c80 Am")