| time | topic |
|---|---|
| 1:30-1:45 | Why, philosophy and benefits |
| 1:45-2:05 | Organising data to map variables to plots |
| 2:05-2:35 | Making a variety of plots |
| 2:35-3:00 | Do but don’t, and cognitive principles |
| 3:00-3:30 | BREAK |
Creating data plots for effective decision-making using statistical inference with R
Why (1/6)
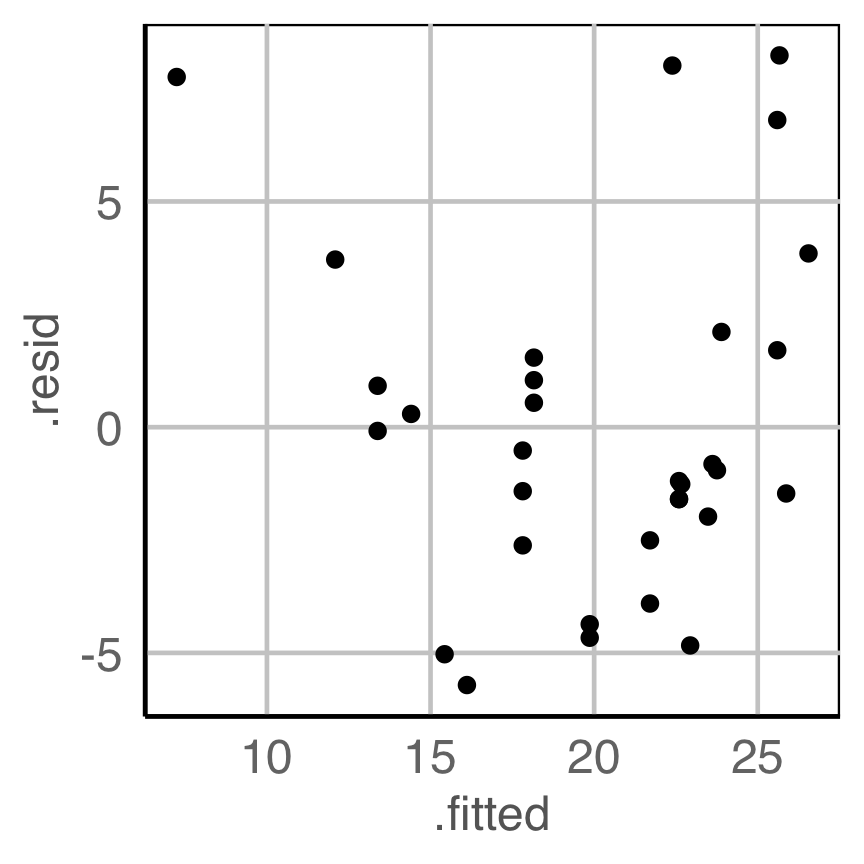
Is there any pattern in the residuals that indicate a problem with the model fit?
Do we need to change the model specification?
Why (2/6)
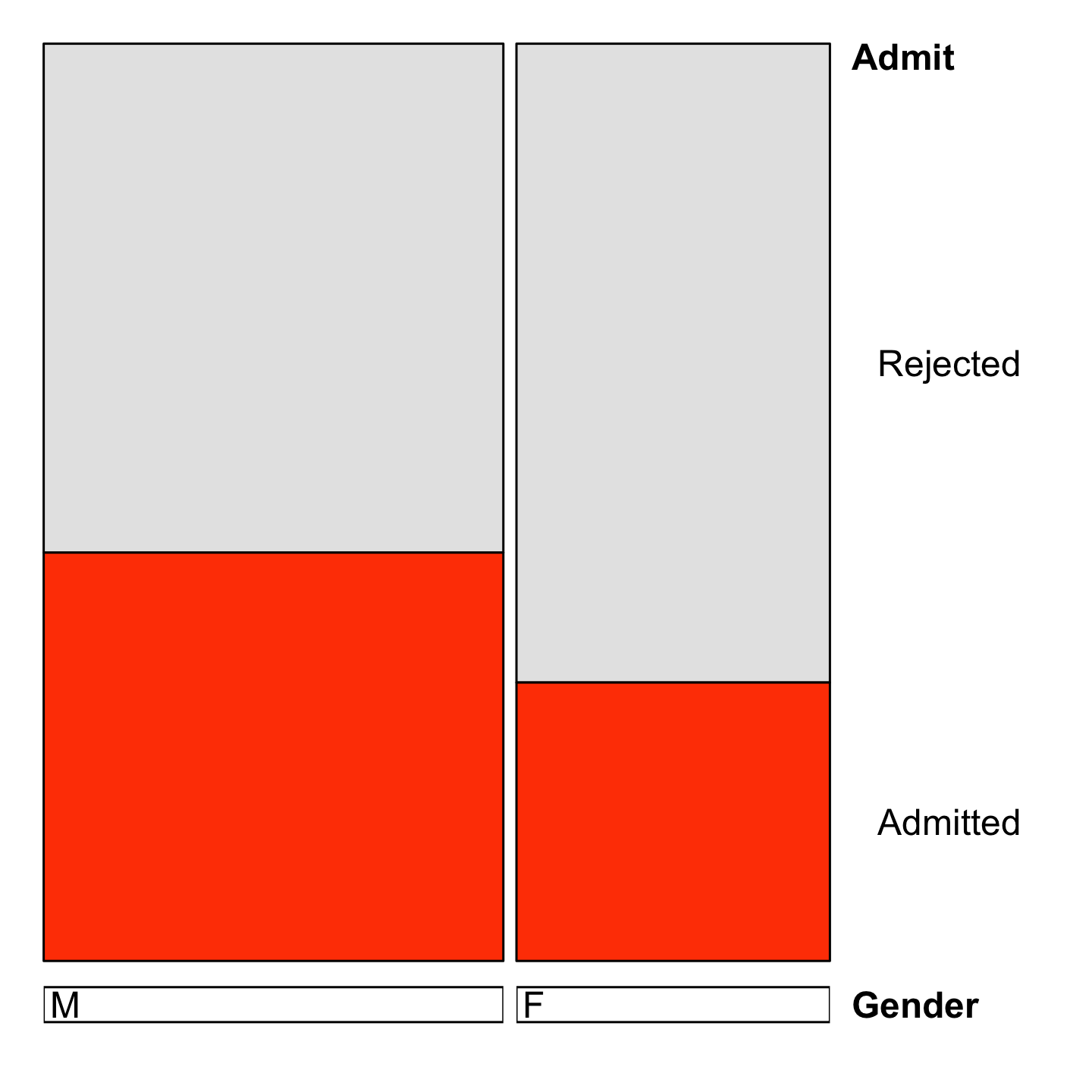
Is there a bias in admissions?
Why (3/6)
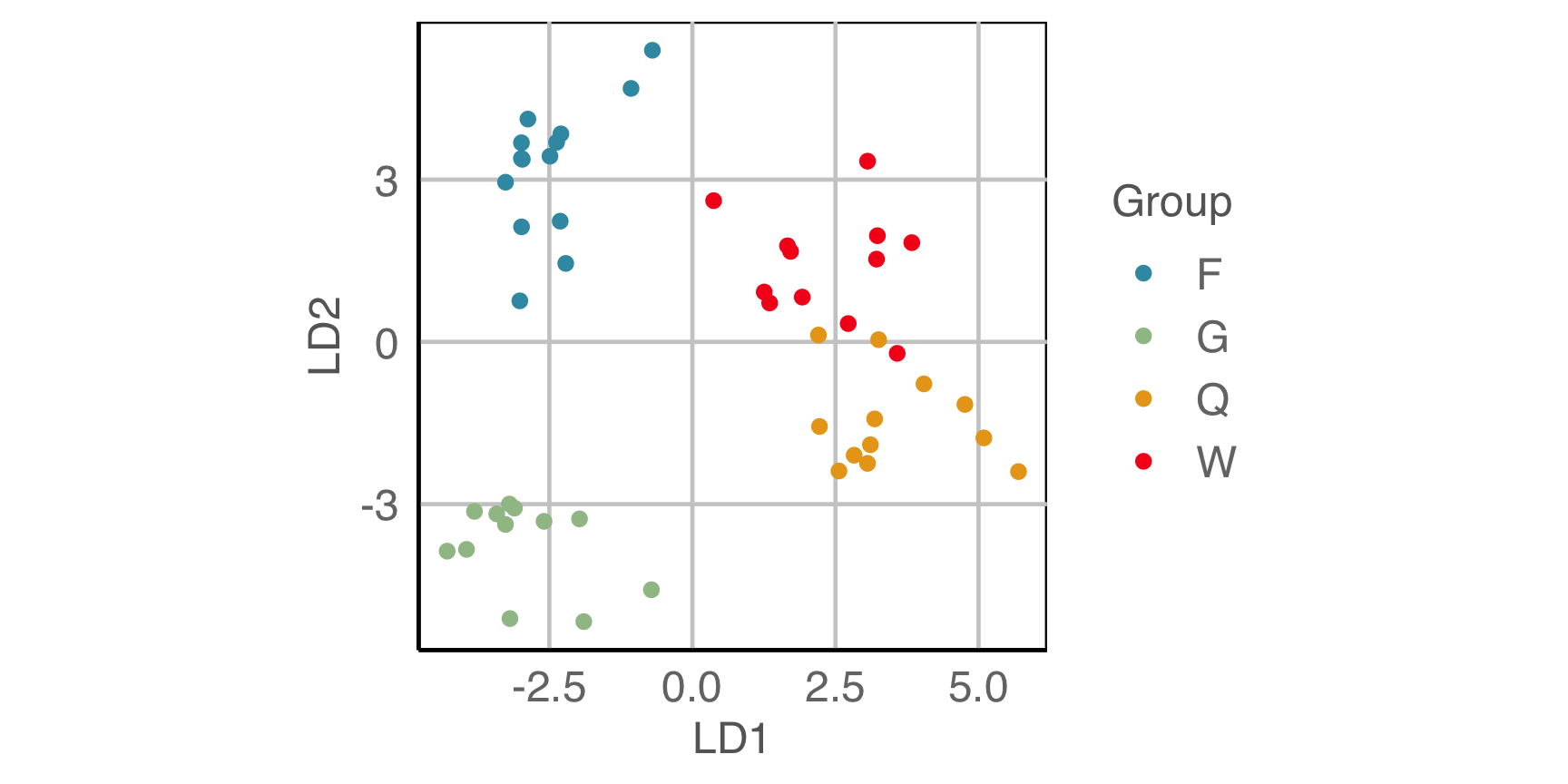
Is there a difference between the species?
Why (4/6)
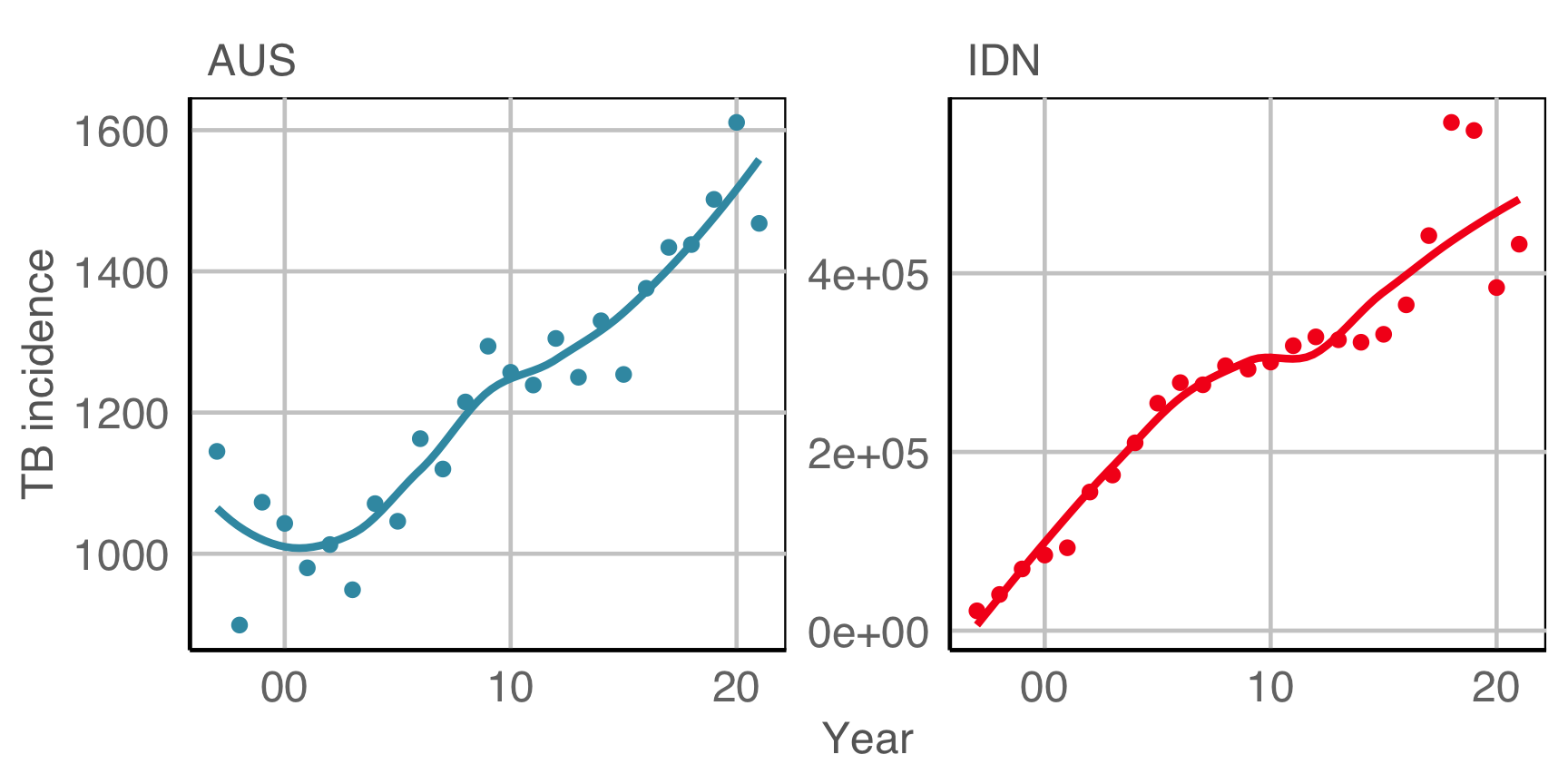
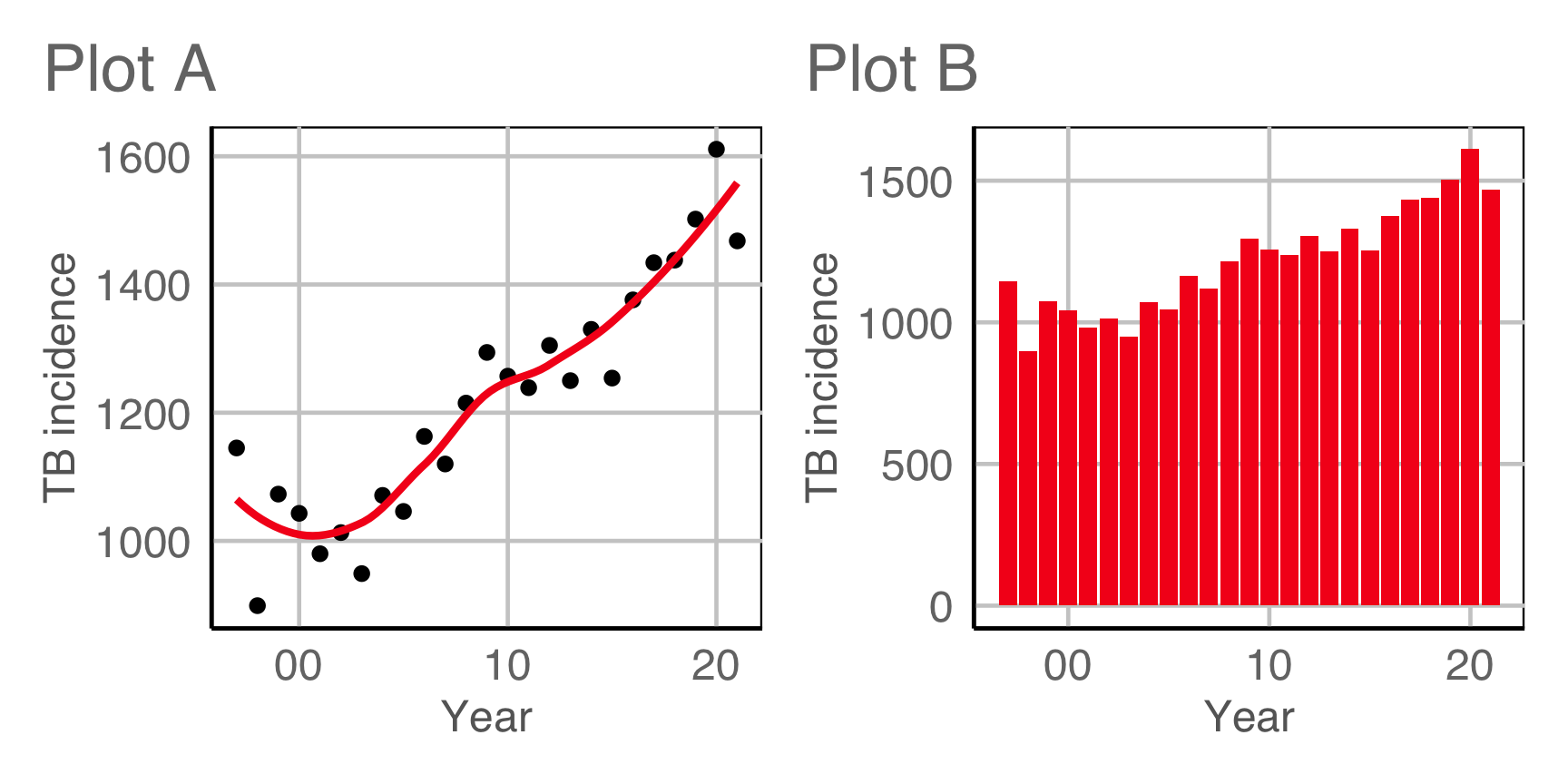
Is TB getting worse? (In Australia and Indonesia)
(From the World Health Organisation (WHO)]
Why (5/6)
Which is the best display to answer the previous question?
Why (6/6)
Which is the best display to answer: what is distribution of thyroid cancer across Australia?
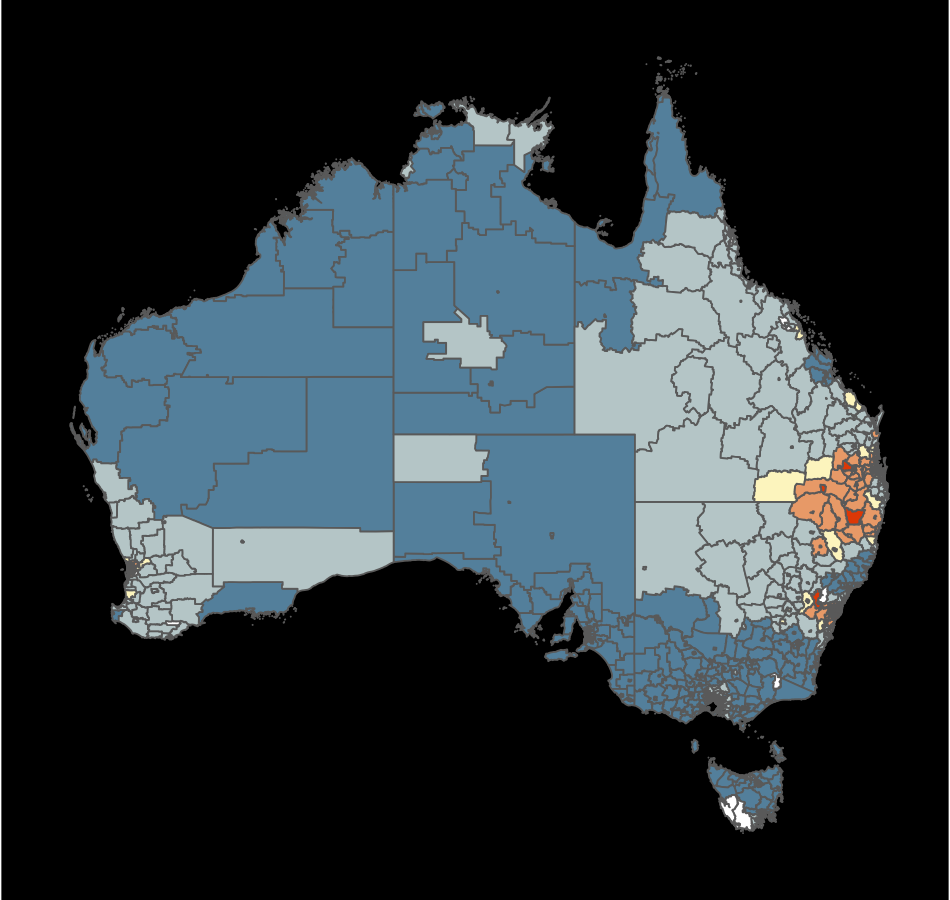
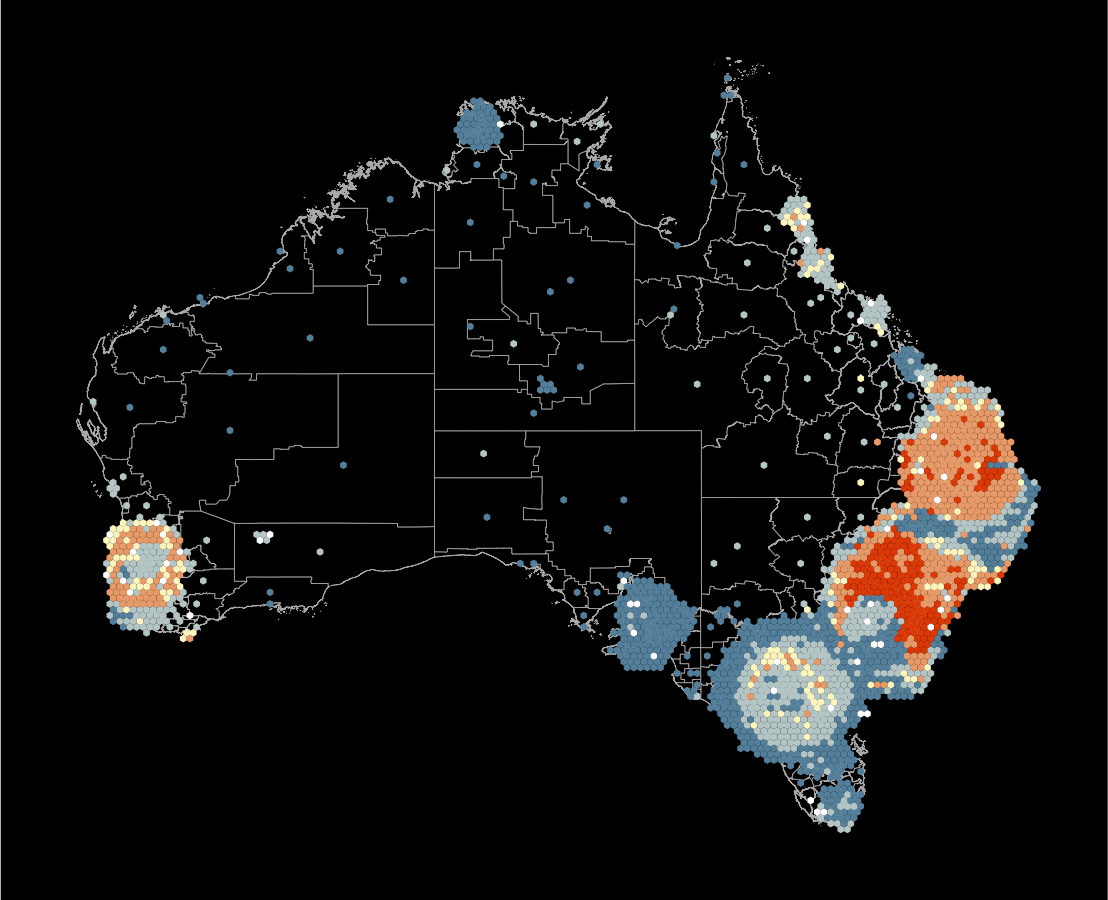
These are the tools you need
![]()
install.packages("ggplot2")or better yet:
install.packages("tidyverse")- Define your plots using a grammar that maps variables in tidy data to elements of the plot.
- Wrangle your data into tidy form for clarity of plot specification.
space

install.packages("nullabor")- Compare your data plot to plots of null data.
- This checks whether what we see is real or spurious.
- Also allows for measuring the effectiveness of one plot design vs another.
Tidy data
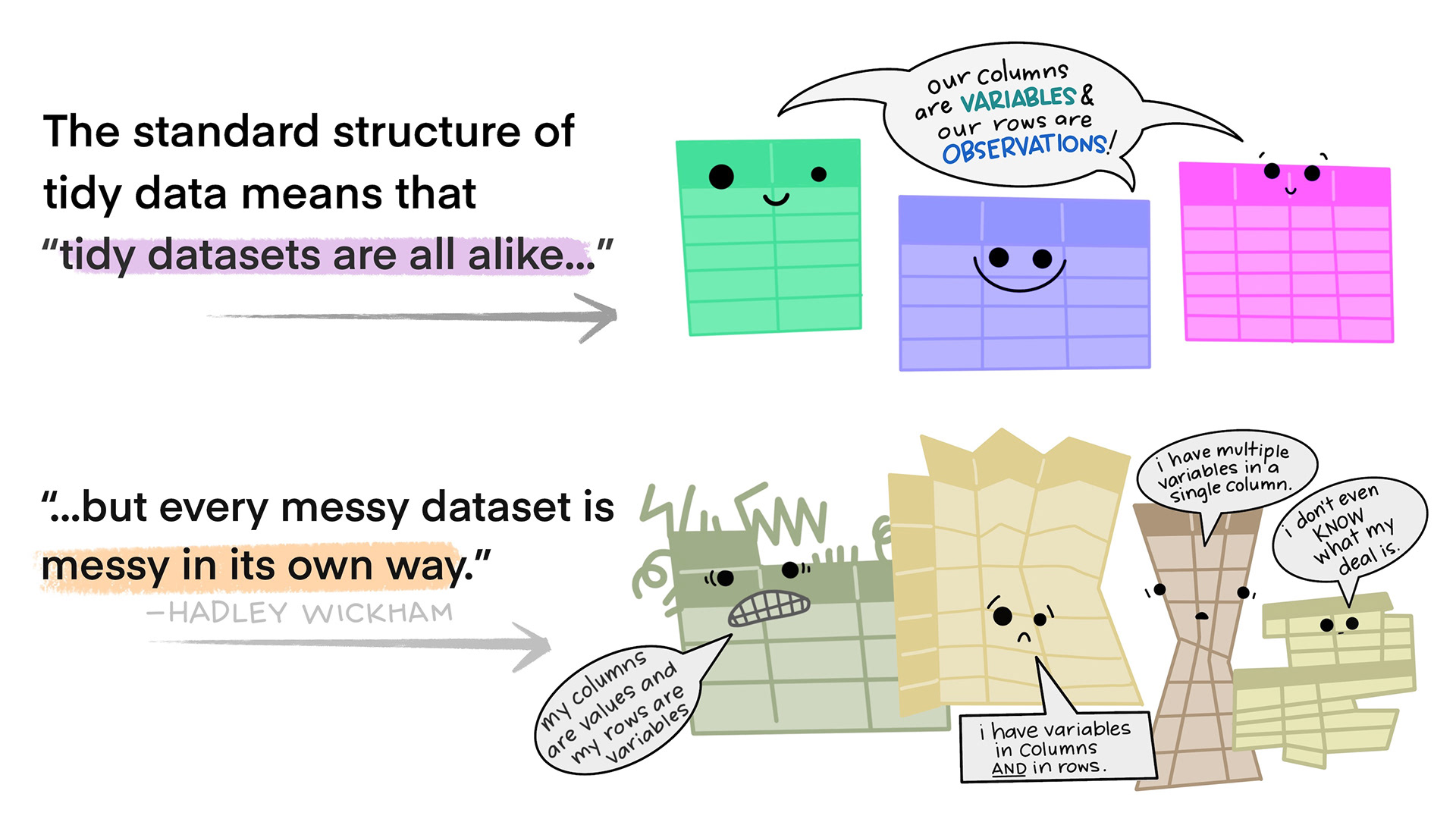
- Each variable forms a column
- Each observation forms a row
- Each type of observational unit forms a table. If you have data on multiple levels (e.g. data about houses and data about the rooms within those houses), these should be in separate tables.
Illustrations from the Openscapes blog Tidy Data for reproducibility, efficiency, and collaboration by Julia Lowndes and Allison Horst
Example 1A
How are variables mapped to create this plot?
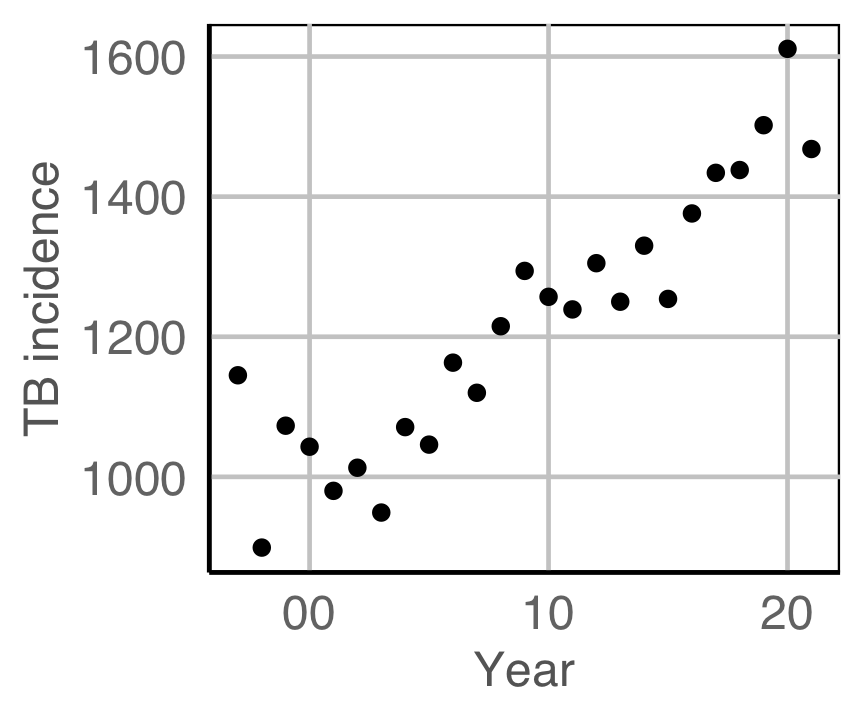
Code for AUS TB plot
ggplot(tb_aus,
aes(x=year,
y=c_newinc)) +
geom_point() +
scale_x_continuous("Year",
breaks = seq(1980, 2020, 10),
labels = c("80", "90", "00", "10", "20")) +
ylab("TB incidence") Example 1B
How are variables mapped to create this plot?
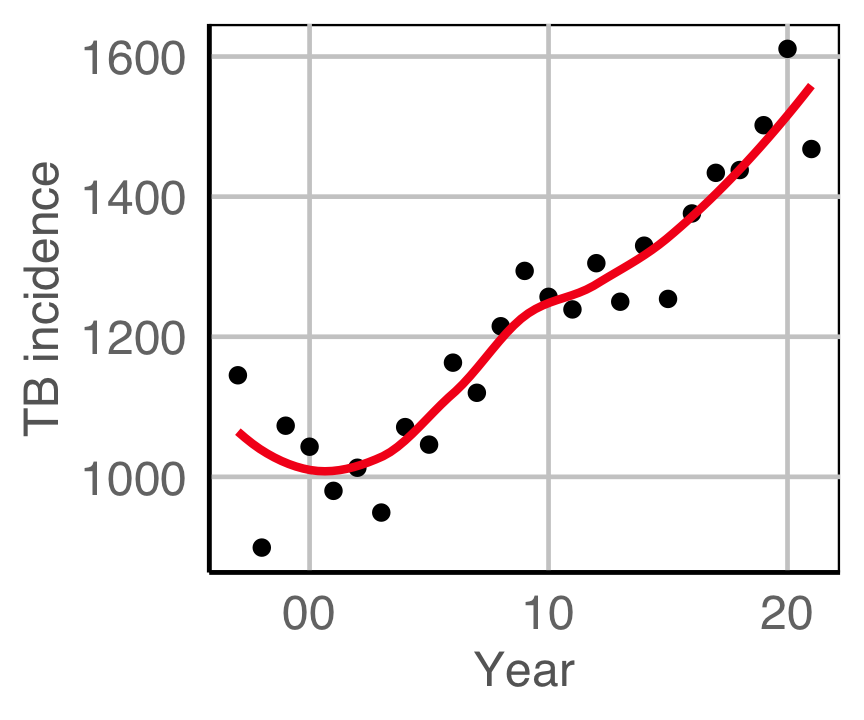
Code for AUS TB plot
ggplot(tb_aus, aes(x=year, y=c_newinc)) +
geom_point() +
geom_smooth(se=F, colour="#F5191C") +
scale_x_continuous("Year", breaks = seq(1980, 2020, 10), labels = c("80", "90", "00", "10", "20")) +
ylab("TB incidence") Example 2A
How are variables mapped to create this plot?
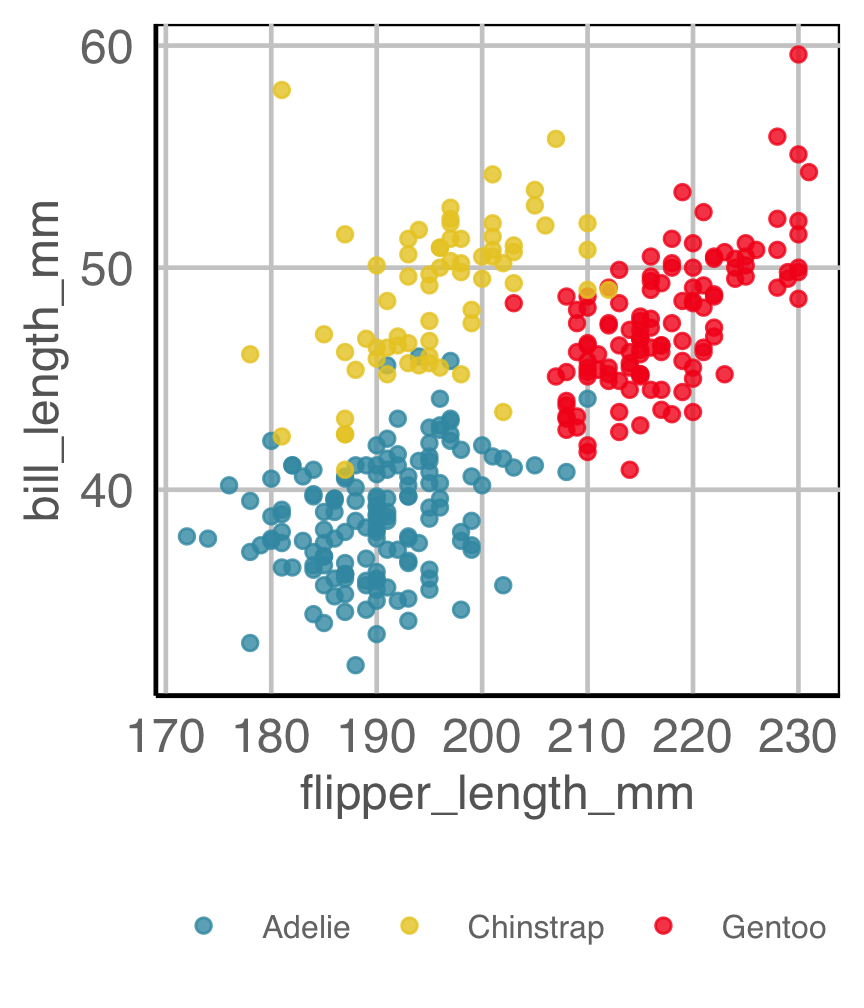
Code for penguins plot
ggplot(penguins,
aes(x=flipper_length_mm,
y=bill_length_mm,
color=species)) +
geom_point(alpha=0.8) +
scale_color_discrete_divergingx(palette="Zissou 1") +
theme(legend.title = element_blank(),
legend.position = "bottom",
legend.direction = "horizontal",
legend.text = element_text(size="8"))Example 2B
How are variables mapped to create this plot?
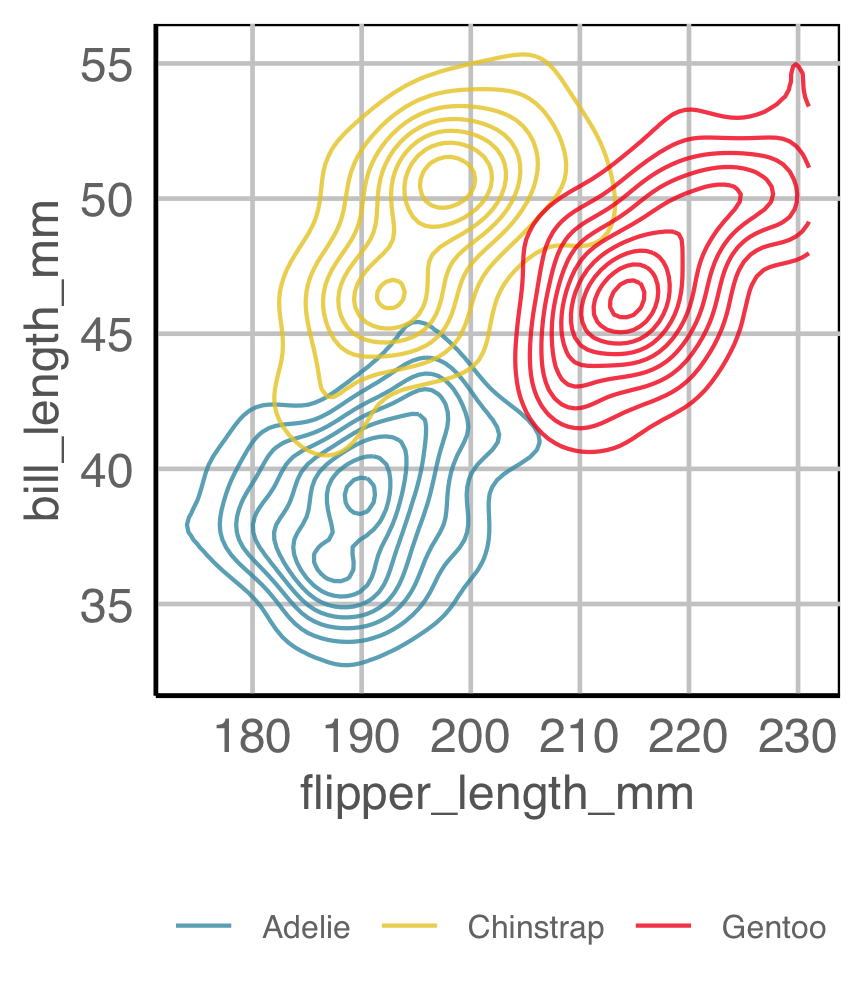
Code for penguins plot
ggplot(penguins,
aes(x=flipper_length_mm,
y=bill_length_mm,
color=species)) +
geom_density2d(alpha=0.8) +
scale_color_discrete_divergingx(palette="Zissou 1") +
theme(legend.title = element_blank(),
legend.position = "bottom",
legend.direction = "horizontal",
legend.text = element_text(size="8"))Example 3 (3/5)
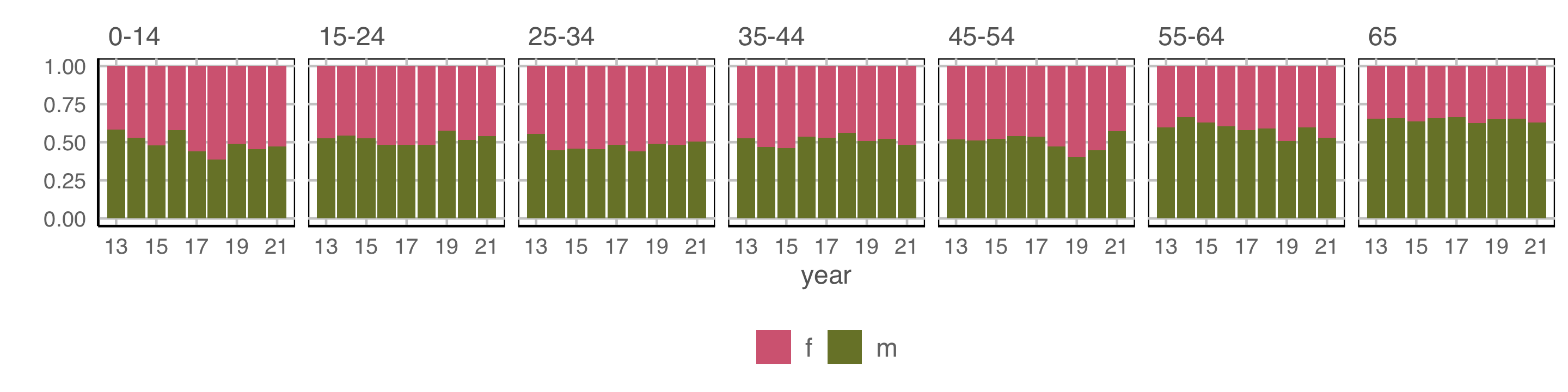
How are variables mapped to create this plot?
geom: bar/position=“fill”
year to x \(~~~~\) count to y \(~~~~\) fill to sex \(~~~~\) facet by age
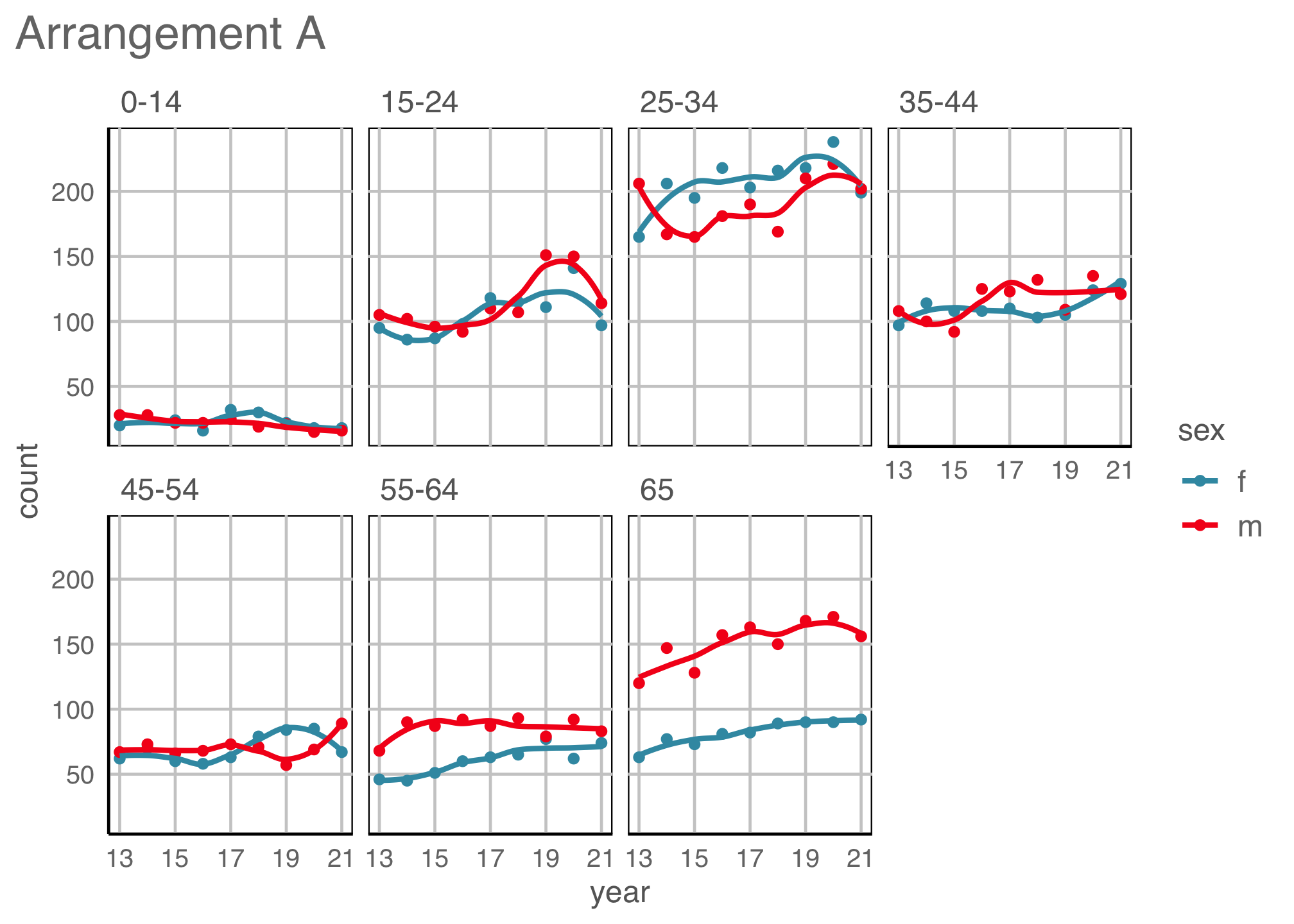
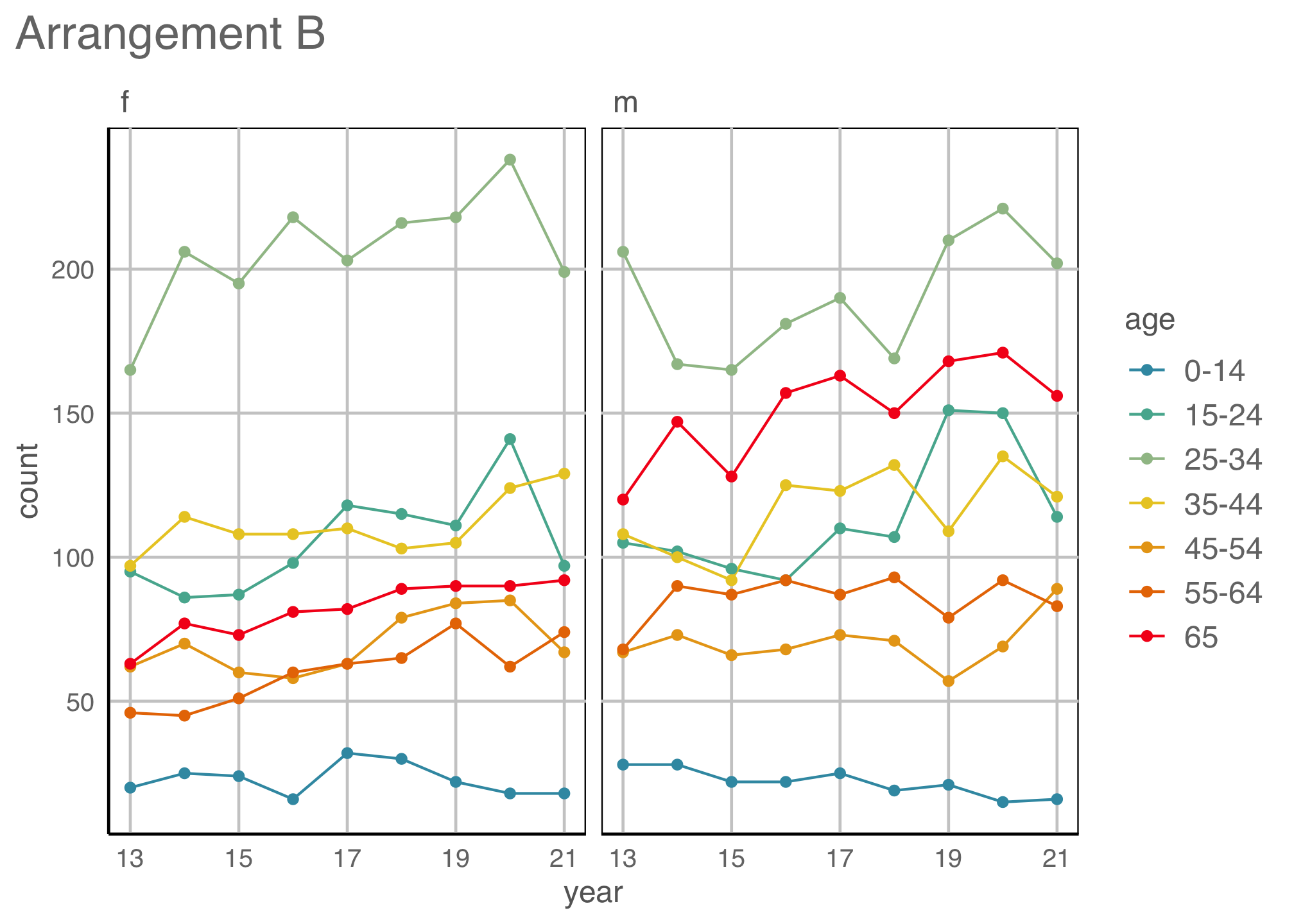
Observations: Relatively equal proportions, with more incidence among males in older population. No clear temporal trend.
Example 3 (4/5)
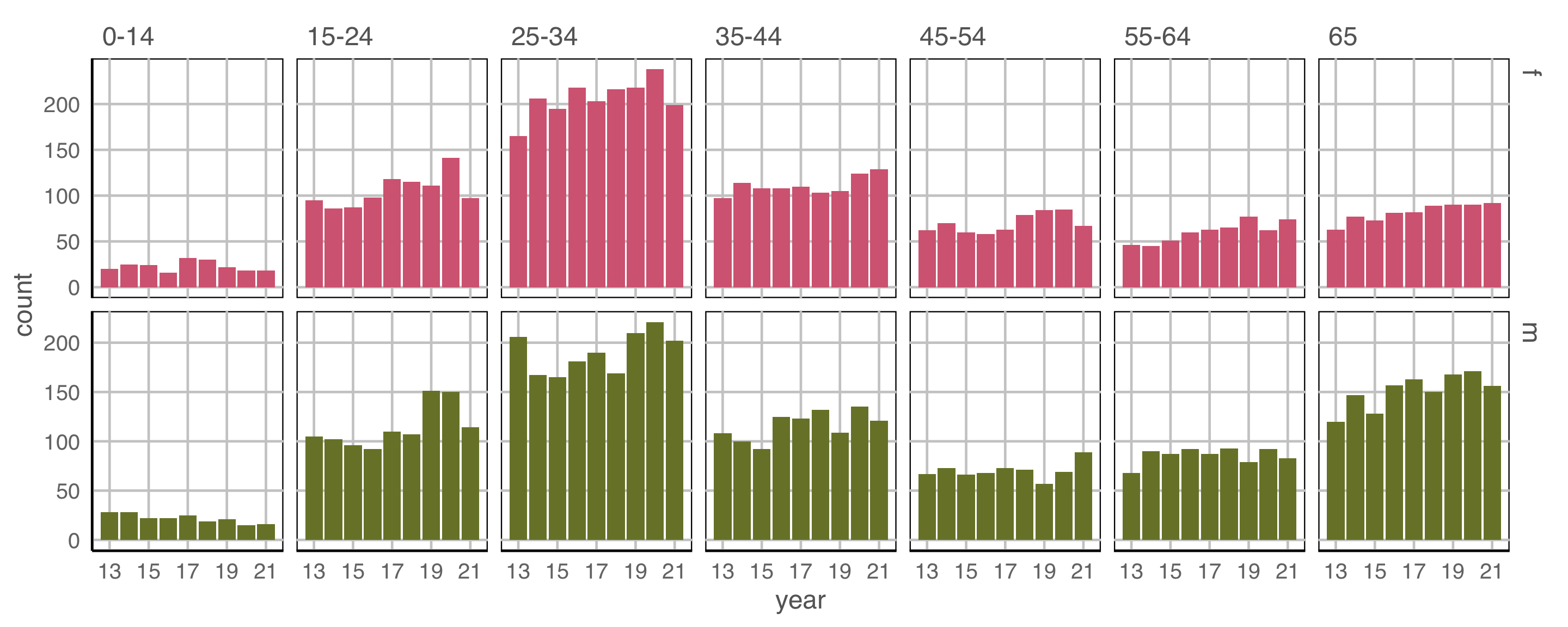
geom: bar
year to x \(~\) count to y \(~\) fill and facet to sex \(~\) facet by age
Incidence is higher among young adult groups, and older males.
Where’s the temporal trend?
Example 3 (5/5)
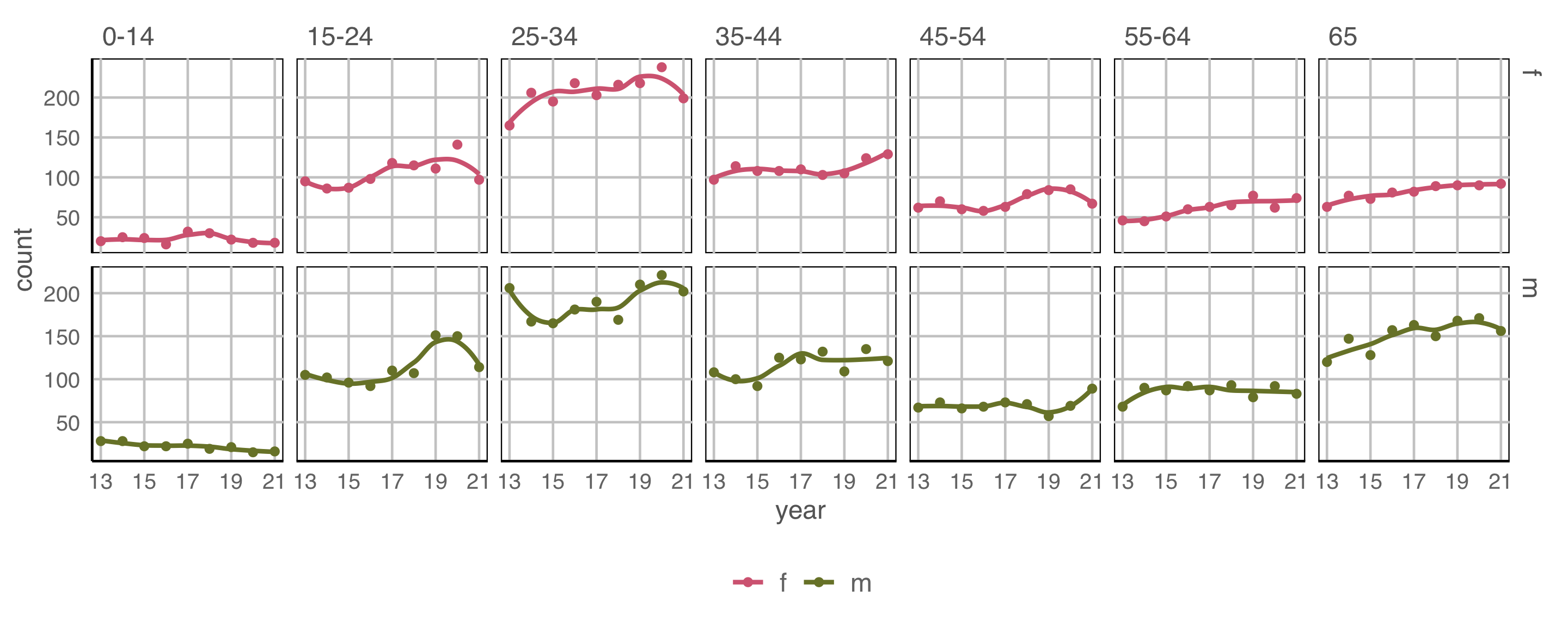
geom: point, smooth
year to x \(~\) count to y \(~\) colour and facet to sex \(~\) facet by age
Temporal trend is only present in some groups.
Re-arrangements
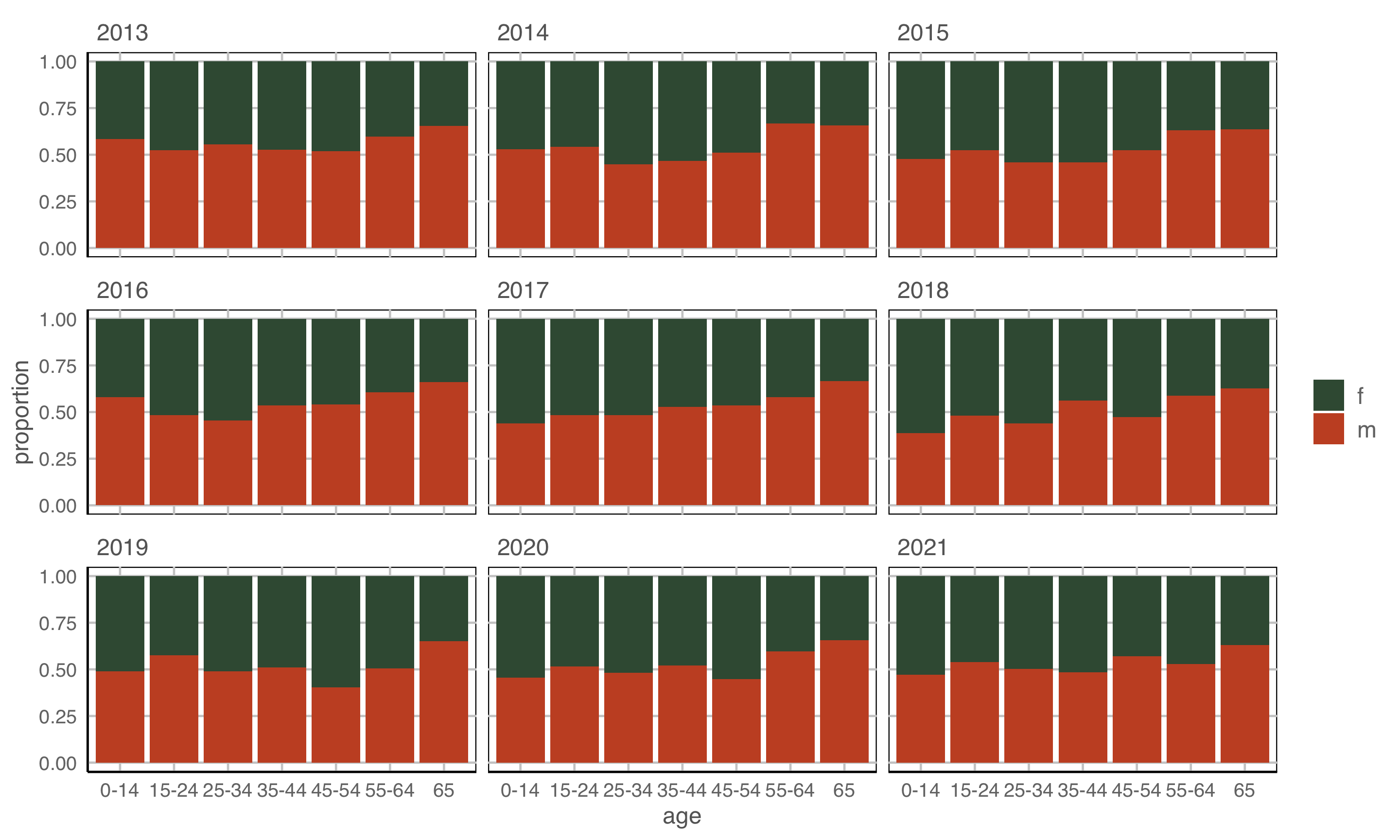
Hierarchy of mappings










Cleveland and McGill (1984)
Illustrations made by Emi Tanaka
Proximity
Place elements that you want to compare close to each other. If there are multiple comparisons to make, you need to decide which one is most important.
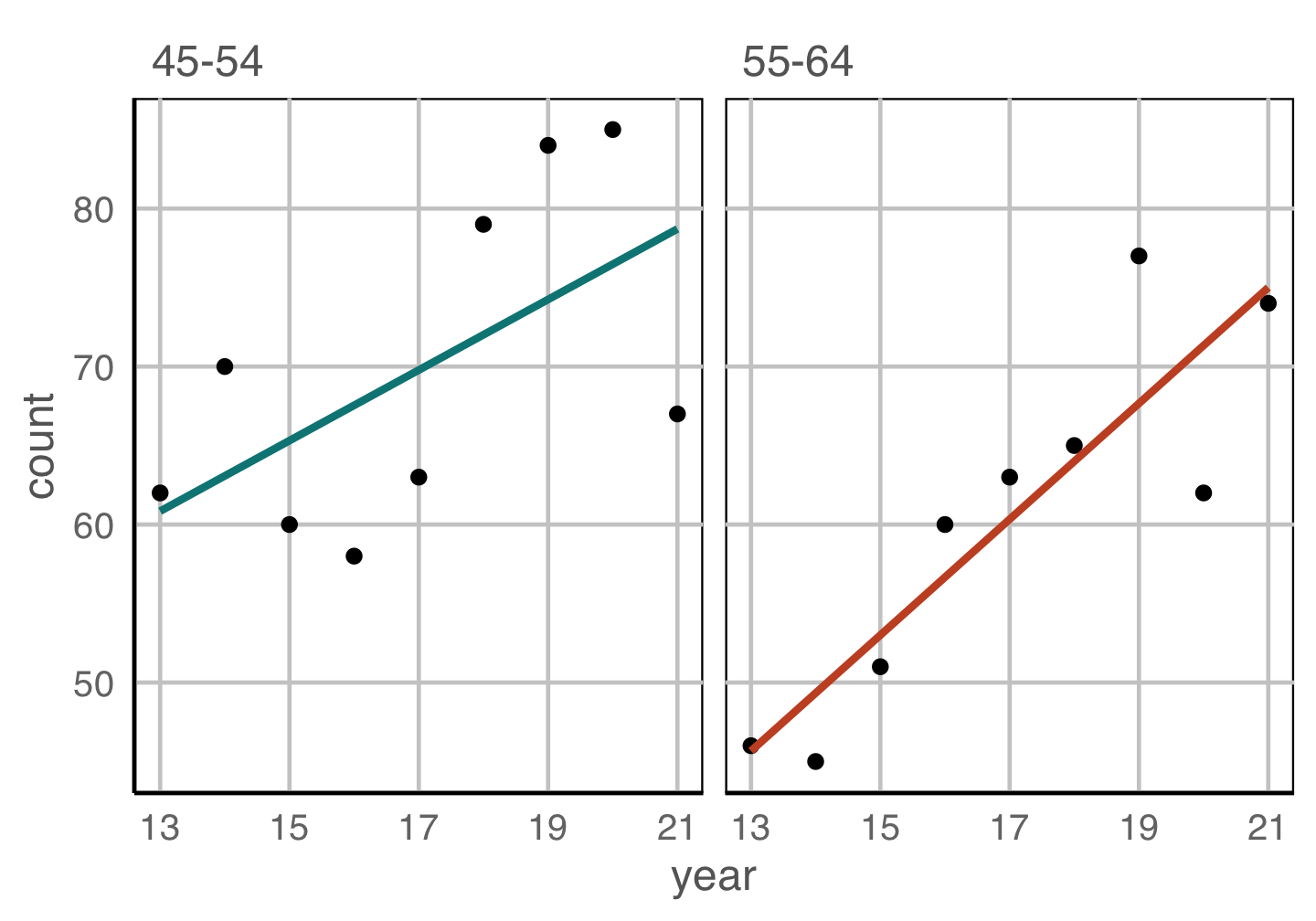
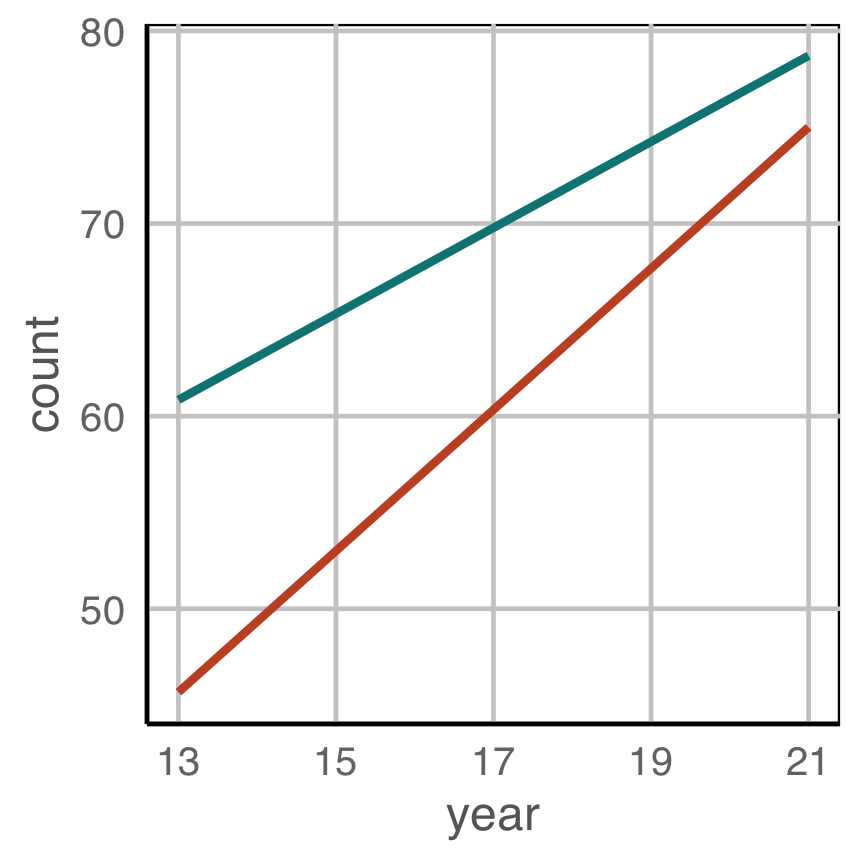
Change blindness
Making comparisons across plots requires the eye to jump from one focal point to another. It may result in not noticing differences.
Exercise
Take the following plot, and make it more difficult to read.
Think about what is it you learn from the plot, and how
- changing the mapping,
- using colour, or
- the geom type
might change what you learn.
library(nullabor)
data(electoral)
ggplot(electoral$polls,
aes(x=Democrat,
y=Margin)) +
geom_boxplot()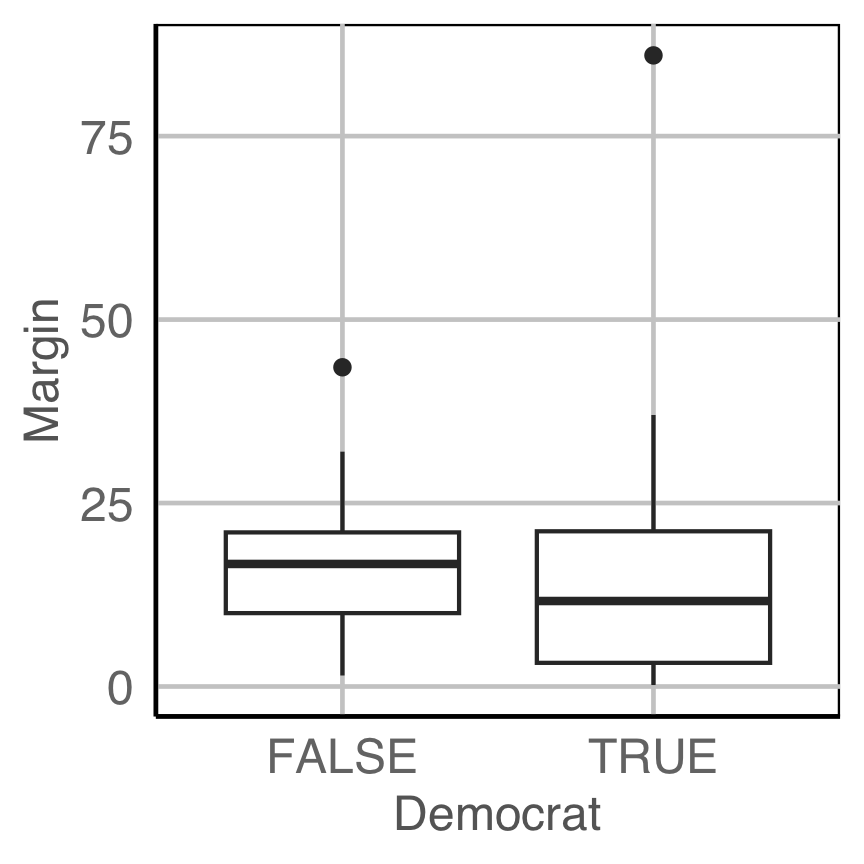
End of session 1

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.