| time | topic |
|---|---|
| 1:30-1:40 | Introduction: What is high-dimensional data, why visualise and overview of methods |
| 1:50-2:10 | Basics of linear projections, and recognising high-d structure |
| 2:10-2:30 | Effectively reducing your data dimension, in association with non-linear dimension reduction |
| 2:30-3:00 | BREAK |
Visualising High-dimensional Data with R
Session 1
What is high-dimensional space?
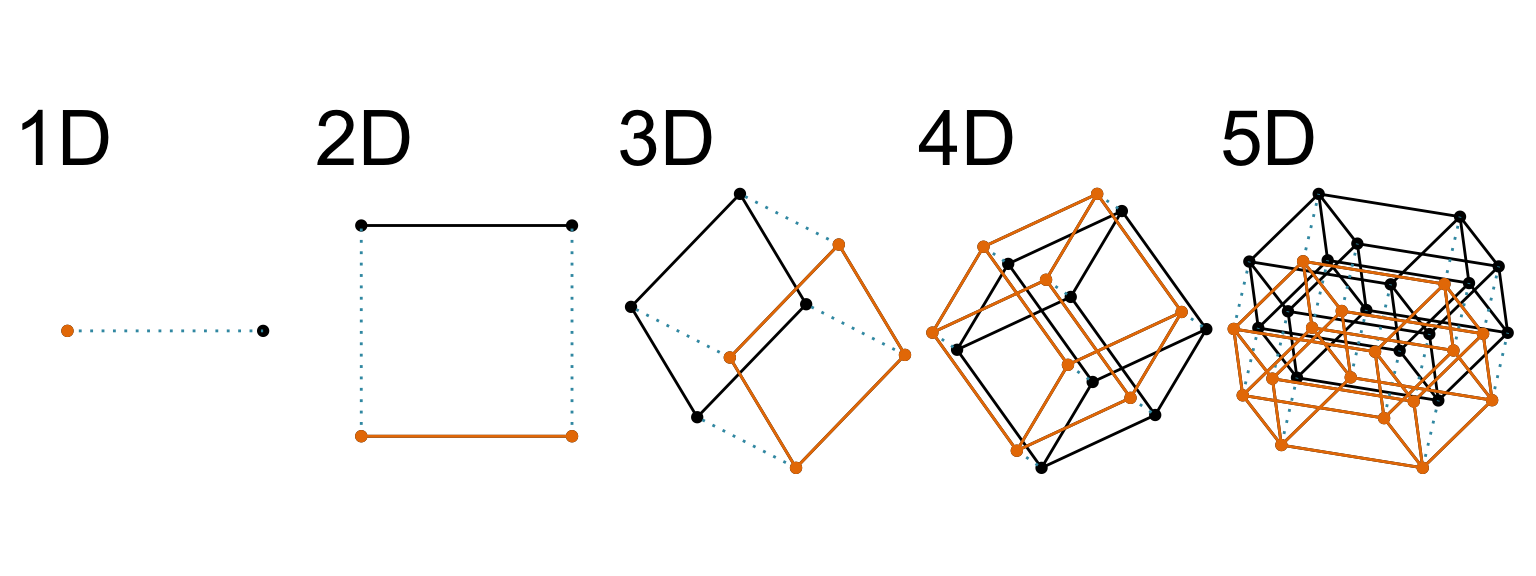
Increasing dimension adds an additional orthogonal axis.
If you want more high-dimensional shapes there is an R package, geozoo, which will generate cubes, spheres, simplices, mobius strips, torii, boy surface, klein bottles, cones, various polytopes, …
And read or watch Flatland: A Romance of Many Dimensions (1884) Edwin Abbott.
Why? (1/2)
Scatterplot matrix
Here, we see linear association, clumping and clustering, potentially some outliers.

Why? (2/2)

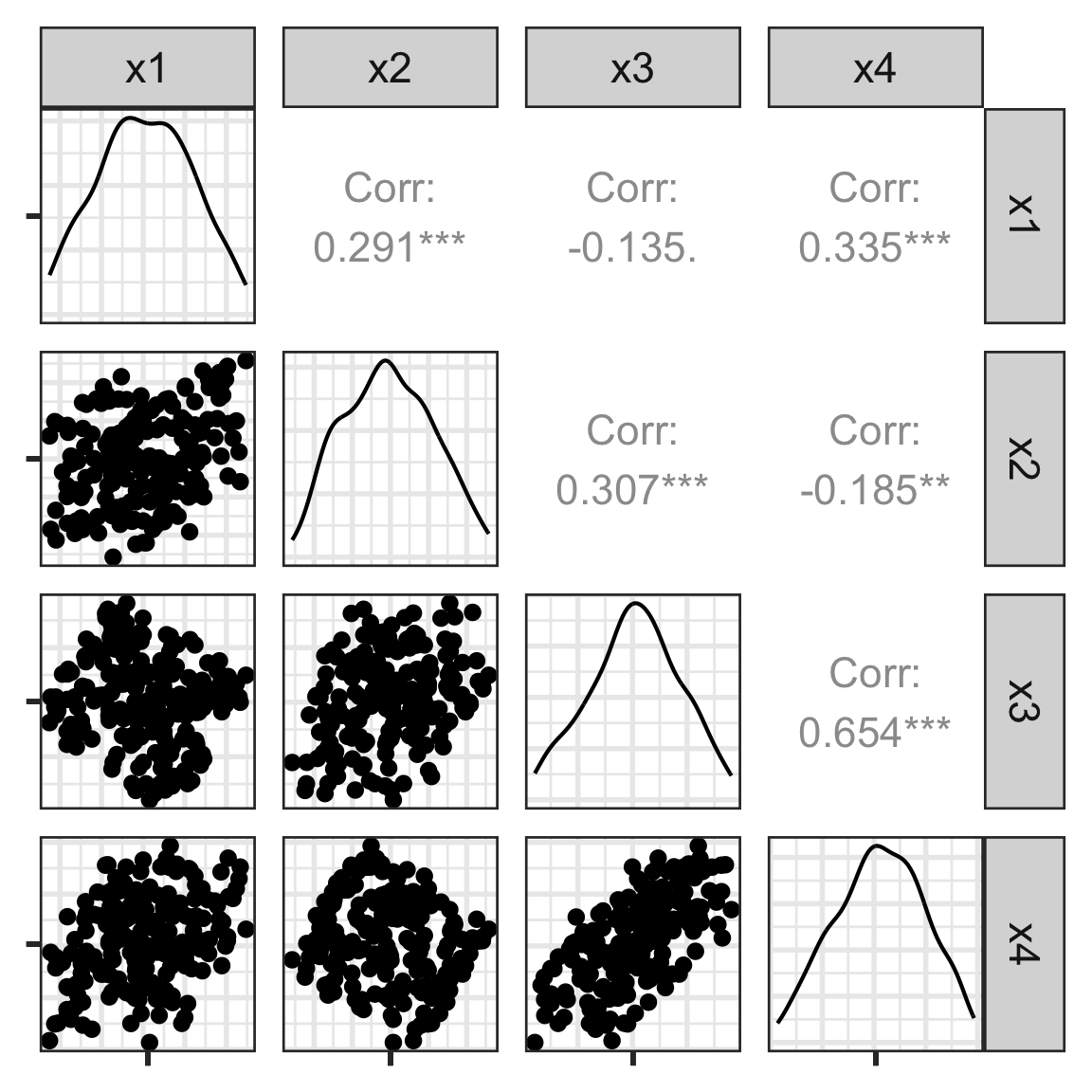
There is an outlier in the data on the right, like the one in the left, but it is hidden in a combination of variables. It’s not visible in any pair of variables.
And help to see the data as a whole
To avoid misinterpretation …

… see the bigger picture!
Image: Sketchplanations.
Tours of linear projections
Data is 2D: \(~~p=2\)
Projection is 1D: \(~~d=1\)\[\begin{eqnarray*} A_{~2\times 1} = \left[ \begin{array}{c} a_{~11} \\ a_{~21}\\ \end{array} \right]_{~2\times 1} \end{eqnarray*}\]
Notice that the values of \(A\) change between (-1, 1). All possible values being shown during the tour.
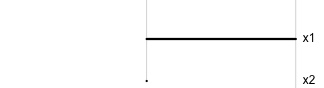
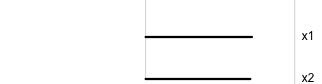
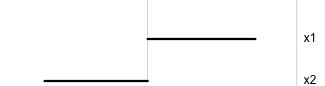
\[\begin{eqnarray*} A = \left[ \begin{array}{c} 1 \\ 0\\ \end{array} \right] ~~~~~~~~~~~~~~~~ A = \left[ \begin{array}{c} 0.7 \\ 0.7\\ \end{array} \right] ~~~~~~~~~~~~~~~~ A = \left[ \begin{array}{c} 0.7 \\ -0.7\\ \end{array} \right] \end{eqnarray*}\]
watching the 1D shadows we can see:
- unimodality
- bimodality, there are two clusters.
What does the 2D data look like? Can you sketch it?
Tours of linear projections

⟵
The 2D data

Tours of linear projections

Data is 3D: \(p=3\)
Projection is 2D: \(d=2\)
\[\begin{eqnarray*} A_{~3\times 2} = \left[ \begin{array}{cc} a_{~11} & a_{~12} \\ a_{~21} & a_{~22}\\ a_{~31} & a_{~32}\\ \end{array} \right]_{~3\times 2} \end{eqnarray*}\]
Notice that the values of \(A\) change between (-1, 1). All possible values being shown during the tour.
See:
- circular shapes
- some transparency, reveals middle
- hole in in some projections
- no clustering
Tours of linear projections
Data is 4D: \(p=4\)
Projection is 2D: \(d=2\)
\[\begin{eqnarray*} A_{~4\times 2} = \left[ \begin{array}{cc} a_{~11} & a_{~12} \\ a_{~21} & a_{~22}\\ a_{~31} & a_{~32}\\ a_{~41} & a_{~42}\\ \end{array} \right]_{~4\times 2} \end{eqnarray*}\]
How many clusters do you see?
- three, right?
- one separated, and two very close,
- and they each have an elliptical shape.
- do you also see an outlier or two?
Intuitively, tours are like …


How to save a tour
To save as an animated gif:
set.seed(645)
render_gif(penguins_sub[,1:4],
grand_tour(),
display_xy(col="#EC5C00",
half_range=3.8,
axes="bottomleft", cex=2.5),
gif_file = "gifs/penguins1.gif",
apf = 1/60,
frames = 1500,
width = 500,
height = 400)What is dimensionality?

When an axis extends out of a direction where the points are collapsed, it means that this variable is partially responsible for the reduced dimension.
In high-dimensions
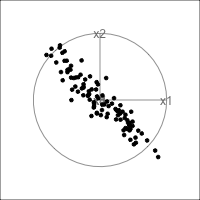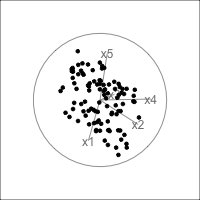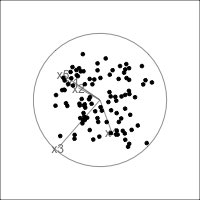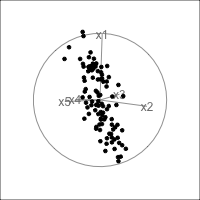
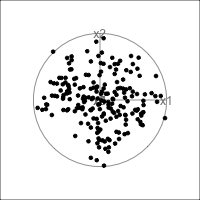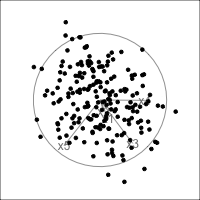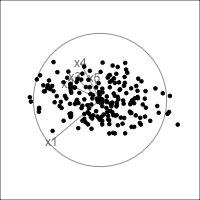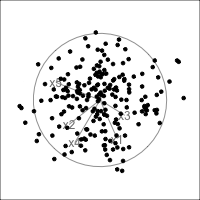
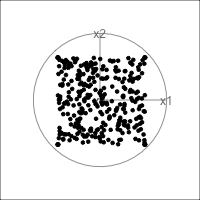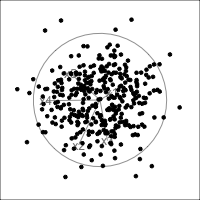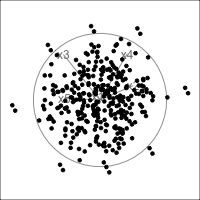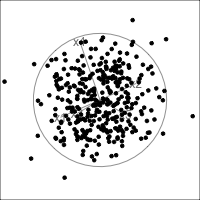
Principal component analysis (PCA) will detect these dimensionalities.
Some data is basically univariate

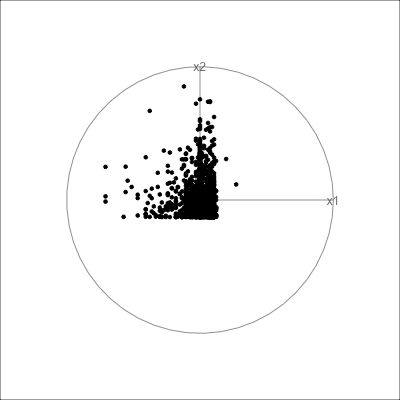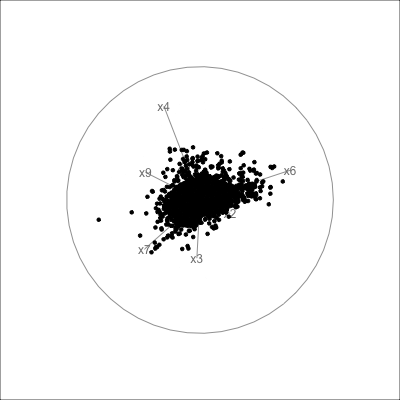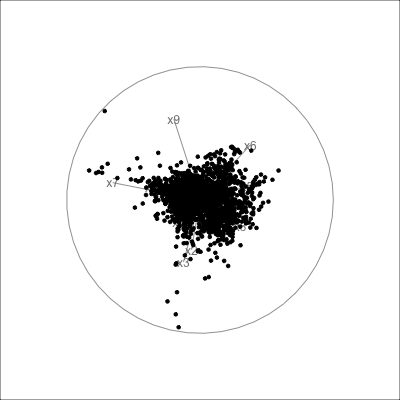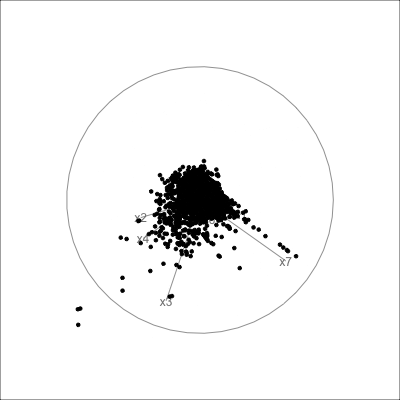
Example: womens’ track records (1/3)

Source: Johnson and Wichern, Applied multivariate analysis
Example: PCA summary (2/3)
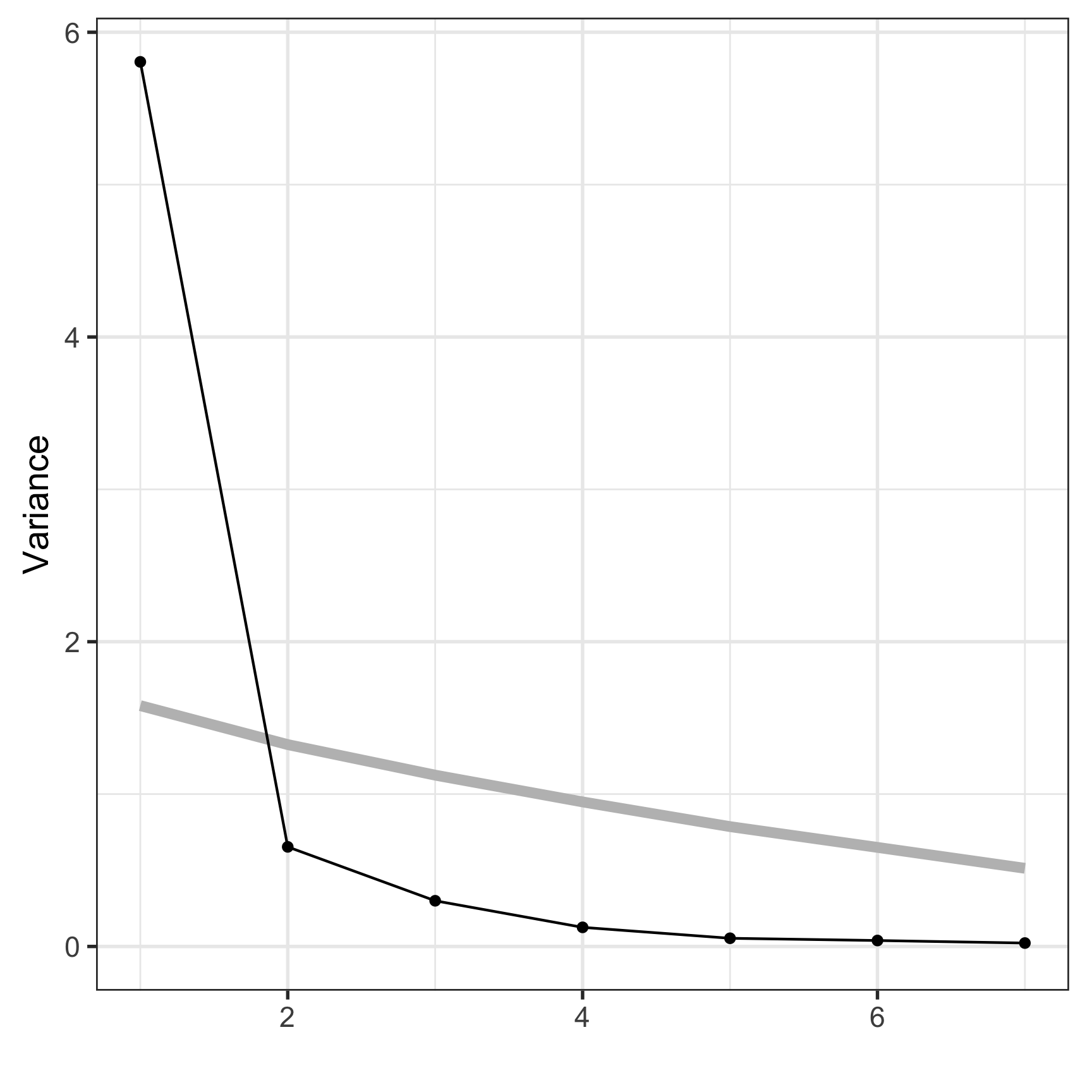
Variances/eigenvalues
[1] 5.806 0.654 0.300 0.125 0.054 0.039 0.022Component coefficients
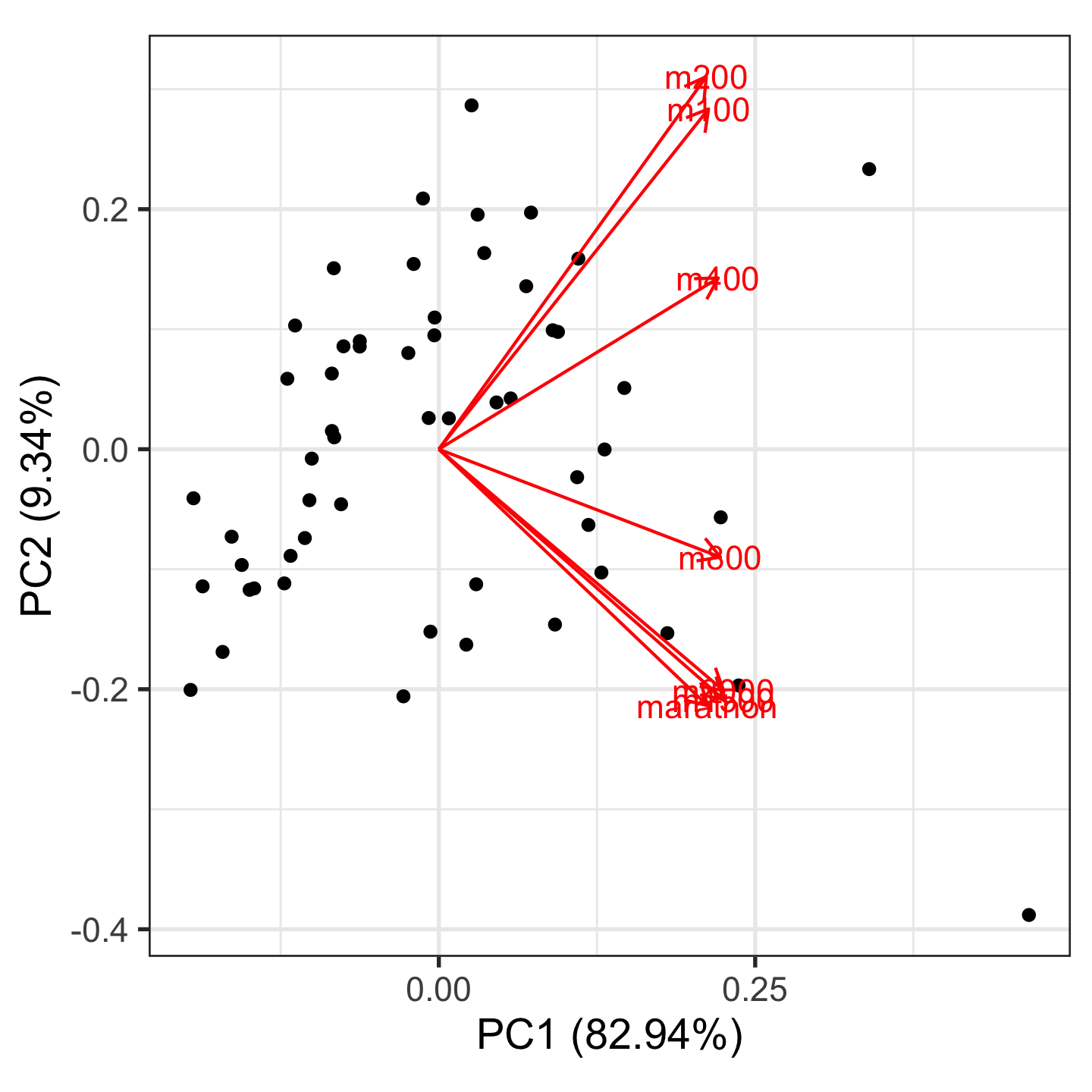
PC1 PC2 PC3 PC4
m100 0.37 0.49 -0.286 0.319
m200 0.37 0.54 -0.230 -0.083
m400 0.38 0.25 0.515 -0.347
m800 0.38 -0.16 0.585 -0.042
m1500 0.39 -0.36 0.013 0.430
m3000 0.39 -0.35 -0.153 0.363
marathon 0.37 -0.37 -0.484 -0.672How many PCs?
Example: Visualise (3/3)
Biplot: data in the model space
2D model in data space
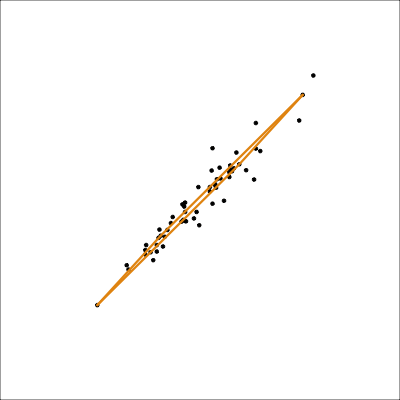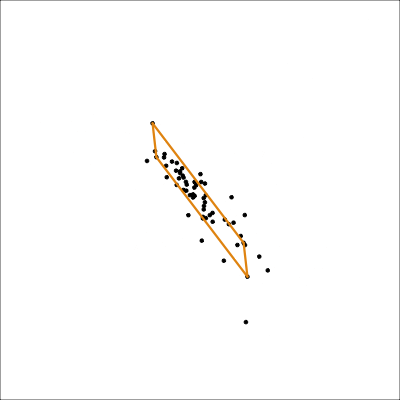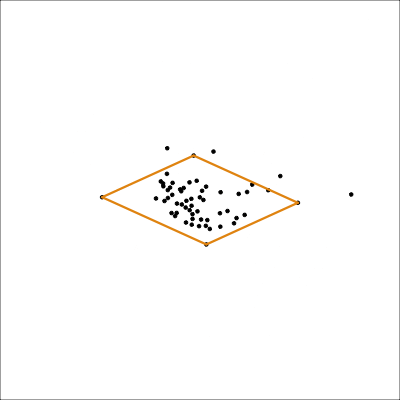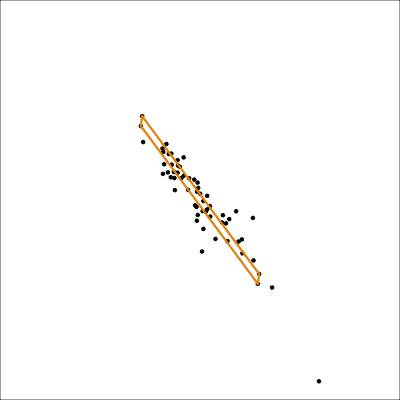
track_model <- mulgar::pca_model(track_std_pca, d=2, s=2)
track_all <- rbind(track_model$points, track_std[,1:7])
animate_xy(track_all, edges=track_model$edges,
edges.col="#E7950F",
edges.width=3,
axes="off")End of session 1

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.